



|
|
|
|
|
This page discusses a paper by Hauer and Kondrak (1) that was already published in 2016, but in January 2018 it suddenly attracted a significant amount of media attention, where it was hailed as the solution of the Voynich MS text, and a victory of Artificial Intelligence (AI) over 600 years of human failure (2). The present discussion will try to establish whether this was justified or not. More critical reviews also started appearing after a few days (3). In any case, the authors clearly state, in Section 5.4 of their paper, that has the title "Decipherment Experiments":
The results presented in this section could be interpreted either as tantalizing clues for Hebrew as the source language of the VMS, or simply as artifacts of the combinatorial power of anagramming and language models.
From this alone, it would appear that the media 'hype' was not warranted by the conclusions of the authors. In the following, the paper is analysed in some more detail, also with the intention of making it accessible to people who are not well versed in mathematics or NLP.
The paper presents a number of methods (algorithms) for analysing an encoded text. This is not specifically dedicated to the Voynich MS, but is of general interest. Several of these algorithms have been developed by the authors, and are shown to have some superior properties when compared with existing algorithms from other researchers. These algorithms have several different functions, in particular:
For the first function, the authors present three different algorithms, respectively in Sections 3.1, 3.2 and 3.3 of the paper. They analyse how well these algorithms perform by trying them out and comparing the results against each other. For this analysis, known plain text in 380 different languages have been encoded using a MASC without anagramming. This analysis is described in Section 3.4.
It should be stressed at this point that this collection of known plain texts is a very interesting resource because of the very large number of different languages involved, but has the serious disadvantage that the texts are relatively short, with an average length of approx. 11,000 characters as stated by the authors.
The second function, which is called 'Script Decipherment' is described in Section 4.1. The third function 'Anagram Decoder' is described in Section 4.2. Here, the authors introduce the capability to decode anagrams also in case vowels have been removed from the plain text as part of the encoding process. The anagrams (also known as a transposition cipher) are restricted to moving the characters within individual words.
This sequence of three steps is then applied to the Voynich MS text, after it has again been tested, in this case on five long source texts in distinct languages: English, Bulgarian, German, Greek and Spanish.
Let us now look at some of the more interesting aspects of the individual steps, and at the same time see how this has been applied to the Voynich MS text.
The paper presents an analysis of the text of the Voynich MS, that is based on a number of assumptions. These assumptions may not be shared by everyone, but at least they are clearly stated, and it means that any result is valid specifically under these assumptions. The assumptions are also tentatively justified by the authors, referring to earlier work. These assumptions are:
Without dwelling too much on these assumptions, it is known from earlier studies that the Voynich MS text does not have the characteristics of a simple cipher (4), and specifically is not a MASC of a well-known European language (old or new) (5). However, there are many languages of interest for this MS that have not yet been compared in detail with the Voynich MS text, so the analysis by Hauer and Kondrak is of great interest, even when we don't expect the best match to be Latin, or modern English or German.
In Section 5.1, the authors explain that the Voynich MS text that has been used in all analyses is:
43 pages of the manuscript in the type B handwriting (VMS-B), investigated by Reddy and Knight (2011), which we obtained directly from the authors. It contains 17,597 words and 95,465 characters, transcribed into 35 characters of the Currier alphabet (d'Imperio, 1978) (6).
The reference to "type B" is a classification of the text properties (better known as the "Currier language") rather than the handwriting. Roughtly speaking, the pages in the MS can be largely subdivided into three classes, one with text statistics known as Currier-A, a second as as Currier-B and a third as 'undefined'. It is known (7) that Currier-A and Currier-B use the same character set and share many common words, but there are distinct differences in character and especially bigram frequency distributions. This means that any result from the article would strictly speaking only be valid for the "Currier-B" language.
Initially, I had some doubt that this transliterated (rather than transcribed) text is really only Currier-B language, but using some later indications in the article, and knowing which transliteration file was used by Reddy and Knight (8), (which includes both Currier languages), it could be established that this file includes the text from the 20 so-called biological pages (fols. 75-84) and 23 recipes pages (fols. 103-116r) of the MS (9), and these are strictly Currier-B language. By the character count, this text represents over 60% of the entire MS text.
Even more importantly, the text that is used has been expressed in one particular transliteration alphabet, i.e. one particular way to represent the Voynich MS text in alphanumerical characters. Historically, several different alphabets have been used, and four of these have been used for major transliteration efforts. This is explained in significant detail on this page, where the alphabet used by the authors is the one named "Currier" (10). The other three important alphabets are "FSG", "Eva" and "v101".
Without trying to decide which of the four is best, it is certain that the statistical properties of the tranliterated text is significantly different between the four of them. Currier uses 35 different symbols, while FSG and Eva have 25 (see also further below). This means again, that the result is strictly speaking only valid for the Currier transliteration, but even more importantly, we must accept that there is great uncertainty whether this actually represents the set of plain text characters in the Voynich MS. This puts the results of the entire study on a fairly uncertain foundation. The way forward for this fundamental problem is to repeat the same analysis for each of the main tranascription alphabets, and see how much the results vary between them.
The Voynich MS text is compared to many sample texts, and the similarity between each pair is expressed as a 'distance'. A greater distance obviously means less similarity. It is computed using the Bhattacharyya distance, which defines the distance between two normalised frequency distributions. (This means that for each of them the sum of the frequencies is equal to one). The distance is zero only if both frequency distributions are identical. In all other cases the distance is greater than zero.
There are two slightly different ways in which this metric is used. For comparing single character frequency distributions, one either has the same alphabet in the two texts, so the character frequencies can be compared directly. When one of the texts is assumed to be the result of a MASC, its alphabet is no longer known, and in this case, the frequency distribitions are both sorted from high to low before computing the distance. For comparisons of the Voynich MS text with sample texts, this is always how it is done. By the nature of this sorting, the frequency distributions all tend to look rather similar, in a qualitative sort of way.
The first method that the authors propose for language identification is the (intuitive) comparison of the character frequency distributions. This method is tested with known plain texts in 380 languages that have been subjected to a MASC. It is demonstrated (in Table 1) that this works in roughly 70% of all cases. It is important that this method is independent of any transposition (anagramming) that may have been applied to the text. The success rate of this method is considered by the authors (in Section 5.2) as sub-optimal. This is undoubtedly due to the fact that all distributions are rather similar. The method is not a good discriminator. While the best match is not guessed correctly in 30% of the cases, it should still be true that the matching language should be very close to the top of the list. We will come back to this important point further below.
It may be of interest to look at a few single character distribution graphs. The following two graphs show that the distributions for the Currier and Eva transliterations of the Voynich MS text are quite different:
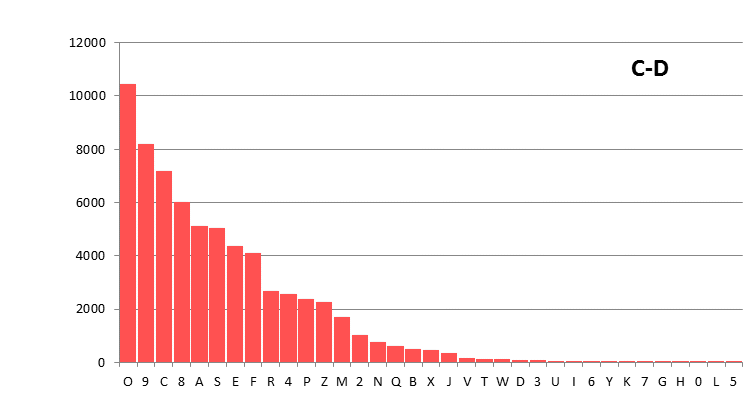
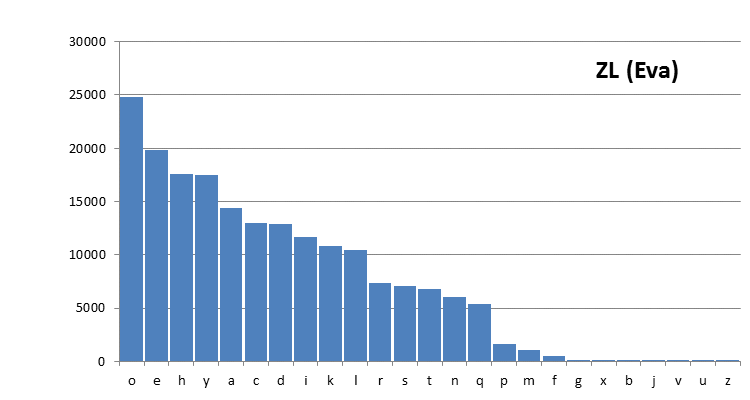
These graphs are part of this page at the present site, where more examples are provided (11). This stresses the main issue about uncertainty of the transliterations that was highlighted already before.
A second method for language identification, that is equally independent of the application of character transposition (anagramming) is clearly explained in Section 3.2 (12). Words are decomposed into character patterns expressed as counts. Paraphrasing the paper, the word "seems" has two times 'e', two times 's' and one time 'm', so it is represented by the pattern '(2,2,1)'. These numbers are sorted high to low. The distance is again computed using the Bhattacharyya distance, but of course in this case the frequency patterns must not be sorted according to their frequency, but matched individually. The authors do not mention this point, probably because it is obvious. Testing this method in the same way as before gives a much improved success rate in finding the original language (see Table 1), of just under 90%.
The third method of language identification is called 'Trial Decipherment', and I have not been able to completely understand its explanation in Section 3.3, in particular the relevance of the 10 least common bigrams. What is important is, that this method will only work for text to which no transposition ciper has been applied. The bigrams are disrupted by the anagramming.
The authors list a few of the highest ranking languages according to the first method. The first language is highly unlikely as it is a new World language. The authors explain that this method is least reliable, so should not be used. Still, it would have been interesting so see some of the numerical values, especially for the languages that are highlighted in the following.
The second method results in a very clear candidate. The character patterns for modern (!) Hebrew are very close to those of the Currier-B language part of the Voynich MS text using the Currier alphabet. This is demonstrated in Figure 4, where the horizontal scale confirms the statement from the authors that Hebrew is closer to the Voynich MS text than to any of the other languages. This is rather surprising since the Hebrew alphabet has 22 different symbols (13) while the Currier transliteration uses 35 symbols. We will come back to that later.
For the third method, the authors write that the results depend a lot on different parameter settings of the algorithm, but Hebrew and Esperanto tend to appear high in the list rather consistently. This qualitative remark is seen as a confirmation of the second result, but as we will see later, the Voynich MS text is finally considered to be anagrammed Hebrew, in which case the result of the third test becomes meaningless. A more important confirmation would have been that Hebrew also appears high in the list for the first method, but this is unfortunately not indicated.
The paper has a short but interesting section related to alphagrams, which highlights a very unusual feature of the Voynich MS text, but can otherwise be skipped for the present purpose. The discussion about the resolution of anagrams with or without vowel removal shows that the algorithms of the authors are quite effective.
Finally, in Section 5.4, the authors provide a translation of the first line of the Voynich MS text, assuming anagrammed Hebrew, and matching the Hebrew words with a corpus of text from older Hebrew, that was listed in Table 4 ("Tanach"). This poses another problem. The first folio of the Voynich MS is in Currier-A language, which is sufficiently different from Currier-B, on which all analysis in the article has been used, to cast doubt on the applicability of these analyses for this line. This test could have been done on a line of Voynich MS text in Currier-B language (14).
In any case, ignoring this, we may look at the word-for-word mapping, which is shown in the table below. The characters can be mapped to each other, with the exception of the two pairs of Currier 'M' / 'P' and Currier 'S' / 'V'. (15).

Here, again, we are facing the problem of the mis-match of alphabet size between Hebrew (22) and the Currier transliteration (35). It is not explained how the Currier alphabet maps to Hebrew. The first line of the MS, that is translated in the paper, only has 14 different characters, so this problem is circumvented.
The impact of this issue is not clear. In case the 13 additional characters in the Currier alphabet, that cannot be mapped back to Hebrew, are to be treated as 'nulls' (i.e. they are not to be converted to Hebrew but ignored), the effective character pattern statistic of the Voynich text would change, and the very close match with Hebrew in the second language identification method would disappear, or at least be reduced. Alternatively, if several Currier symbols should be mapped to single Hebrew characters, again the character pattern statistic will change. However, we don't know by how much, and the frequency of the 13 least common characters in the Currier transliteration may even be negligible. Furthermore, Hebrew has different character forms for some word final characters, so if one judges a Hebrew text simply by the Unicode character representations, the alphabet size increases from 22 to 27 (16).
The paper tentatively suggests that the Voynich MS text was generated by anagramming a Hebrew text on a word by word basis, and applying a mono-alphabetic substitution cipher (MASC). If this were correct, one should be able to take an existing, and ideally old, Hebrew text, apply this procedure, and arrive at a text that shares all important statistics with the Voynich MS text (Currier language B and Currier transliteration alphabet). Unfortunately, this is not attempted, and I would like to argue that this will not be possible. The Voynich MS has a number of features that are not addressed in the paper.
The most important one is that the character bigram entropy is anomalously low (17). The only way that this could happen in the proposed scenario is that this is the result of the anagramming, but earlier experiments in this direction have not been successful. The bigram entropy, which is associated with peculiar word patterns in the Voynich MS text, is simply too low.
We remain without an explanation for the very close match of Hebrew word patterns with those of the Currier transliteration of the Voynich MS. One pre-requisite for this is that the word length distribution has to be very similar. It would be of interest to check this property for all source texts separately.
The first thing that should be undertaken is to repeat the analyses using the other available transliterations of the Voynich MS, and see how much the result depends on this. Further work should then take this into account.
![]()
|
|
|
|
|