



|
|
|
|
|
Capt. Prescott Currier proposed that the pages of the Voynich Manuscript are written in two different 'languages', which he called 'A' and 'B' (1). Whether these are in fact two different languages is an open point. Alternative possibilities are that the MS is in one language, but the differences are due to different dialects or even just different subject matter. A third possibility exists if the Voynich text is in code. In that case the differences may still be due to one of the above differences in the plaintext, or otherwise the encryption method leaves some freedom and different personal styles are responsible for the difference.
An important aspect is the fact that the pages written in language A also show a different hand than the ones written in language B. One may assume they were either written by at least two different people, or by one person at different times.
If one accepts the spaces in the Voynich manuscript as separator (for words, syllables or anything else), the text may be broken up into small character groups which will be called words or word tokens in the following. When two words are the same, we will call them of the same word type.
In the following, the word types in the A and B sections will be studied in order to draw some conclusions about the differences between the two 'languages'. Some of the results shown here have also been deduced from other statistics and presented by members of the early Voynich Manuscript mailing list. A similar study was also made by Mary D'Imperio, looking at the single character frequency distribution (2).
The most common word type in the A corpus is or in Currier notation: 8AM (3). In the B corpus, the most frequent word is , or in Currier: SC89. A peculiar fact is that the latter word does not occur at all in the A corpus, whereas is relatively frequent in B as well. In general, words tend to either occur in both languages or they occur in 'B' only. There is a very short list of moderate-frequency words that occur only in language A. Had the split between A and B languages coincided with the apparent split in subject matter (apparent from the illustrations), this would make sense. This is not the case, however, since the herbal illustrations have text in both languages, so we do have a reason to question whether the text is related to the illustrations at all.
The data used in the analysis was taken from the >>raw FSG transliteration available at Jim Reeds' web site (4). The text has been converted to the Currier alphabet (which does not alter the statistics) and split into single files per page, using Th.Petersen's page numbering scheme (nrs 1 to 234) (5). For each page, all words were sorted alphabetically. The correlation between two pages was defined as the number of word tokens common to both pages, i.e. if any word types occurred several times on one page, each occurrence was counted. The following example may explain this more clearly:
Page 1: Ape Ape Bear Cat Cat Cat
Page 2: Ape Ape Ape Boar Cat
The number of common words is three: two times Ape and one Cat. Obviously, the number of common words depends heavily on the number of words on each page. Since the number of words per page is highly variable (and correlated with the language used, B pages being much more verbose), a normalisation factor needs to be used. This factor was chosen as a constant divided by the square root of the product of the number of words on the two pages being compared. This may not be a perfect method, and suggestions for finding a better 'rule' would be appreciated.
In the following figure, the correlation between any pair of pages is displayed in colour. Black means no words were available (page missing in FSG transliteration). The colour scale is (low to high correlation): blue-green-yellow-orange-red-magenta. Page 1 (f1r) is on the top left of the graph, while page 234 (f116r) is at the bottom right.
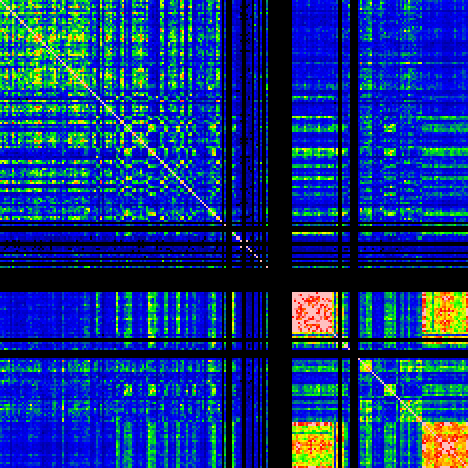
The most prominent features are some bright squares of highly-correlated pages, in the lower right corner of the figure. The brightest square (magenta and red) is the biological section, which is known to be the most consistent piece of text (in B language). We may call this variety Bio-B.
The square in the corner represents the recipes (stars) section, also in B language. It shows a little more variety, especially when looking at the correlation between the stars and biological section. Since it has been suggested that the stars section may have one paragraph for every day of the year, one might venture to think that there is a seasonal effect to be observed here. To test this, the same figure has been made, not basing statistics on all words of the page, but the first 200 only, thus eliminating the need for the uncertain normalisation factor. The result is given below.
From this figure it seems more likely that the observed feature is page-related. The section comprises pages 212 through 234 (where 235 is f116v, not included), or ff. 103-116 (with 109 and 110 missing). The pages that also appear to be in Bio-B 'dialect' are those of ff. 103, 107, 108, 111,112 and 116, which are three bifolia. The other three bifolia with ff. 104, 105, 106, 113, 114 and 115 use a more varied vocabulary, but are not more correlated with A-language pages.
The astronomical and cosmological sections are not well represented in the FSG transliteration, and no conclusion can be drawn about them. The herbal section (before the biological section) and the mixed herbal/pharmaceutical section (between the biological and stars section), show the expected checkerboard pattern for A and B pages. There is no clear evidence for any pages in a third language, which would be visible as a set of pages with low correlation to both A and B pages. There is, however, one other interesting observation to be made: pages 183-185 (all in <f89>) show a correlation with both A and B pages.
The next step is to quantify more precisely in what way the A and B languages differ from each other, and what are the differences or commonalities between the various 'types' of B language for the different sections. Herbal-B and Bio-B are quite different and half the recipes section is different again. While for the biological and stars sections there is a clear correspondence between the illustrations and the 'language', in the herbal and pharma sections this is not the case. Based on these findings, the following page families or clusters may be tentatively defined:
The subdivision of all pages in these clusters was based on the illustration indications in Jim Reeds' >>checklist which is essentially derived from a table in D'Imperio (6). Note that apparently for all pharmaceutical pages the language has been identified as A. Additionally, the split in the recipes section was made on the basis of the above figures.
In order to quantify the differences between all these dialects, as we may call them, for these six clusters the most frequent words are listed below (using the Currier transliteration), with absolute counts (and the total number of counted words per cluster given in the heading):
Herbal-A Pharma-A Herbal-B Stars-B Stars-Bio Bio-B (7975) (2234) (3335) (5251) (5483) (6696) ---------------------------------------------------------------------- 423 8AM 116 8AM 88 8AM 107 AM 136 4OFCC9 254 ZC89 224 SOE 49 SOE 63 SC89 104 8AM 125 4OFAM 214 SC89 154 SOR 37 SCOE 56 OR 85 4OFAM 116 SC89 194 4OFAM 101 ZOE 36 8AE 53 S89 81 SC89 102 4OFCC89 190 OE 98 Q9 32 OE 50 8AR 66 OPAM 101 8AM 164 4OFC89 95 S9 27 SC9 41 AM 66 OFAM 99 AM 148 4OFCC89 94 ZO 26 OFCOE 41 4OFC89 66 AR 98 OFAM 130 4OE 93 89 25 AM 40 AR 60 AE 93 SC9 112 8AM 88 2 24 4OFCOE 36 ZC89 43 4OPAM 83 ZC89 108 4OFAE 78 8AN 23 OFCC9 36 SX9 41 SCC9 77 ZC9 96 SC9 75 8AR 23 2AM 35 OFAM 39 SOE 72 OFCC9 95 ZC9 63 ZOR 22 SOR 31 OFAR 39 OE 65 AR 78 4OFCC9 61 Z9 21 OR 31 OE 36 ZC89 62 OE 76 8AE 56 SC9 21 4OFCC9 30 89 35 4OFCC89 62 AE 73 2AM 52 QOE 20 SCOR 28 4OFAR 34 SCO 57 OPAM 72 8AR 51 OR 20 SCC9 26 OFC89 34 SC9 52 2AM 61 4OF9 50 4OPS9 20 8AR 26 2AM 34 RAM 46 OPCC9 60 OR 48 8AE 19 ZC9 25 8AE 33 FAM 43 OPC89 57 ESC89 44 OE 17 ZCOE 24 OFAE 32 OR 42 4OFC89 56 OFAM 43 8OE 17 SCO89 22 OPC89 31 8AR 38 RAM 53 4OFAN 42 QOR 16 8OE 20 SCF9 30 OPAR 38 OPAE 53 2OE 39 ZC9 16 4OFOE 20 4OFAM 27 2AM 38 FAM 51 4OPC89 39 4OFS9 16 4OFCO89 19 OPAR 26 EFAM 38 ESC89 49 OPC89 38 OP9 15 XC9 18 SC9 26 4OPAR 38 EFAM 49 89 35 SAM 14 ZCC9 18 FAR 26 4OFSC89 37 SX9 45 4OFC9 35 8AJ 14 8AT 17 Z89 25 S89 37 OFCC89 42 SX9 34 SCOR 14 89 17 OF9 25 4OFAR 37 4OFC9 42 OFC89 34 QC9 12 OFOE 17 8AJ 24 SCOE 36 OPCC89 42 4OFAR 34 8OR 10 SO89 16 OFCC89 24 SCO89 36 4OFAE 41 ZCC89 33 SO 10 SCO 15 OPAE 24 8AT 35 SOE 40 SCC9 33 OF9 10 OFC9 15 FS89 23 4O8AM 34 SCC9 39 OPAM 33 2AM 10 9FCC9 15 9FAR 22 OFAR 32 ZCC9 39 AM 30 SO89 10 8AJ 15 4OFS89 21 SC8AM 32 SCOE 36 4OPCC89 29 OPS9 10 4OFC9 14 O89 21 OPAE 31 OFC89 34 4OPAM 29 OPOE 10 2 13 SOE 21 OFAE 30 4OPAM 33 OFCC89 29 FS9 9 ZOE 13 SO89 21 AT 26 OFAE 32 ZCC9 28 4OP9 9 QC9 13 ORAM 21 4OFCC9 26 FCC89 31 ZX9 27 X9 9 OFAE 13 OPAM 20 OPCC89 25 EFCC89 30 SCOE 27 OPAM 9 OEAM 13 FC89 19 ZCC9 23 OR 30 4OPAE 27 OFAM 9 FOE 12 PC89 18 ORAM 23 EFCC9 29 8OE
The same table has been converted to the Eva transliteration alphabet, and is included below. This version is used in the subsequent summary.
Herbal-A Pharma-A Herbal-B Stars-B Stars-Bio Bio-B (7975) (2234) (3335) (5251) (5483) (6696) ---------------------------------------------------------------------- 423 daiin 116 daiin 88 daiin 107 aiin 136 qokeey 254 shedy 224 chol 49 chol 63 chedy 104 daiin 125 qokaiin 214 chedy 154 chor 37 cheol 56 or 85 qokaiin 116 chedy 194 qokaiin 101 shol 36 dal 53 chdy 81 chedy 102 qokeedy 190 ol 98 cthy 32 ol 50 dar 66 otaiin 101 daiin 164 qokedy 95 chy 27 chey 41 aiin 66 okaiin 99 aiin 148 qokeedy 94 sho 26 okeol 41 qokedy 66 ar 98 okaiin 130 qol 93 dy 25 aiin 40 ar 60 al 93 chey 112 daiin 88 s 24 qokeol 36 shedy 43 qotaiin 83 shedy 108 qokal 78 dain 23 okeey 36 chckhy 41 cheey 77 shey 96 chey 75 dar 23 saiin 35 okaiin 39 chol 72 okeey 95 shey 63 shor 22 chor 31 okar 39 ol 65 ar 78 qokeey 61 shy 21 or 31 ol 36 shedy 62 ol 76 dal 56 chey 21 qokeey 30 dy 35 qokeedy 62 al 73 saiin 52 cthol 20 cheor 28 qokar 34 cheo 57 otaiin 72 dar 51 or 20 cheey 26 okedy 34 chey 52 saiin 61 qoky 50 qotchy 20 dar 26 saiin 34 raiin 46 oteey 60 or 48 dal 19 shey 25 dal 33 kaiin 43 otedy 57 lchedy 44 ol 17 sheol 24 okal 32 or 42 qokedy 56 okaiin 43 dol 17 cheody 22 otedy 31 dar 38 raiin 53 qokain 42 cthor 16 dol 20 cheky 30 otar 38 otal 53 sol 39 shey 16 qokol 20 qokaiin 27 saiin 38 kaiin 51 qotedy 39 qokchy 16 qokeody 19 otar 26 lkaiin 38 lchedy 49 otedy 38 oty 15 ckhey 18 chey 26 qotar 38 lkaiin 49 dy 35 chaiin 14 sheey 18 kar 26 qokchedy 37 chckhy 45 qokey 35 dam 14 dair 17 shdy 25 chdy 37 okeedy 42 chckhy 34 cheor 14 dy 17 oky 25 qokar 37 qokey 42 okedy 34 cthey 12 okol 17 dam 24 cheol 36 oteedy 42 qokar 34 dor 10 chody 16 okeedy 24 cheody 36 qokal 41 sheedy 33 cho 10 cheo 15 otal 24 dair 35 chol 40 cheey 33 oky 10 okey 15 kchdy 23 qodaiin 34 cheey 39 otaiin 33 saiin 10 ykeey 15 ykar 22 okar 32 sheey 39 aiin 30 chody 10 dam 15 qokchdy 21 chedaiin 32 cheol 36 qoteedy 29 otchy 10 qokey 14 ody 21 otal 31 okedy 34 qotaiin 29 otol 10 s 13 chol 21 okal 30 qotaiin 33 okeedy 29 kchy 9 shol 13 chody 21 air 26 okal 32 sheey 28 qoty 9 cthey 13 oraiin 21 qokeey 26 keedy 31 shckhy 27 ckhy 9 okal 13 otaiin 20 oteedy 25 lkeedy 30 cheol 27 otaiin 9 olaiin 13 kedy 19 sheey 23 or 30 qotal 27 okaiin 9 kol 12 tedy 18 oraiin 23 lkeey 29 dol
There is a great deal of information contained in these lists, and the following tentative conclusions may be drawn:
The interpretation of the above data is highly incomplete. To make interpretation of the figure more easily possible, it has been redrawn with the pages sorted 'per cluster' (not included here). It shows that the Herbal-A pages located after the biological section are rather different from the early Herbal-A pages, a feature that should be investigated further.
The experiment should be repeated for texts in known languages. Unfortunately, it is not easy to obtain a page-oriented text as we have of the Voynich manuscript. Instead, different texts should be cut into reasonable-length sections. This could be done for various books of the Vulgate bible, where the language is the same throughout, but the subject-matter can be very different. Based on the result, other experiments, e.g. comparing Latin with French (of which the most frequent word, et, is the same).
It should be very interesting to verify the distribution of certain words over the pages of the Manuscript (e.g. the distribution of all -edy () words in the B sections or that of qokeey () in Stars-Bio.)
Furthermore, the missing sections need to be looked at as well. At first glance, they seem more B-like. Additionally, specific tests for the labels and scattered writing in the Manuscript could be added. This will only be possible when the complete transliteration is available.
|
|
|
|
|