









|
|
|
|
|
|
|
|
|
|
The main mystery of the Voynich MS is clearly its unknown writing. This topic is addressed from three different aspects, on three (sets of) pages:
This page addresses the second part, the transliteration of the text. It summarises historical transliteration efforts and describes the present state of affairs. This page is highly relevant for those who are interested in the interpretation of the Voynich MS text, but it can be skipped by those who are not.
A table at the bottom of this page provides links to the main transliteration files.
There is a second page addressing some more specific topics related to Voynich MS transliteration. Links to it are provided where relevant.
The purpose of transliteration of the text is the conversion of the handwritten text of the Voynich MS into a computer-readable format (file). The aim of this is to allow computer software to analyse the text, for example in order to derive statistics or to aid the interpretation and ideally translation of the text.
Already in the 1976 seminar about the Voynich MS led by Mary D'Imperio (1) this process was called 'transcription' and to my best knowledge this term has been used ever since, in all discussions and publications about the MS. It has also been used throughout this web site until May 2019, when the difference between transcription and transliteration was clarified to me by a professional linguist (2). In his words:
Transcription means a transformation of a text such that it will be substituted by another text made by a well-known alphabet of phonetic symbols. This is only possible in case we already know how the text reads.
[...]
Transliteration is a symbol-by-symbol conversion of one script into another. Transliteration is used for practical purposes, but does not represent any hypothesis on the original pronunciation of the source text. The distinctive feature of transliteration is that it preserves the source text and is reversible. The phonetic data could be totally missing, or not yet available, or irrelevant.
The first time that this type of transliteration was exercised was by William Friedman after WWII, for processing by so-called 'tabulating machines'. Many years before that, in the 1930's, Fr. Th. Petersen of the Catholic University of America already made a complete hand-written copy (in this case a transcription) of the MS using a complete photocopy of the MS and in some cases, in order to transcribe difficult parts, the actual MS. This document, in which he added many interesting annotations, is still preserved in the William F. Friedman collection of the Marshall Library in Lexington (Va) (3).
A transliteration should be clearly distinguished from a proposed translation of the text. The only purpose of a transliteration is to represent each handwritten character in the MS by a symbol in a computer-readable file in a consistent manner. It doesn't really matter which symbol is used for which character. Ever since the 1940's, different people have used different conventions, or transliteration alphabets.
The earliest well-known transliteration of large parts of the Voynich MS was made in the 1940's by the so-called First Study Group (FSG) of William Friedman, which was briefly mentioned here. The group was working from photostatic copies of the pages of the MS, and they worked with a transliteration alphabet agreed by all members of the team. Because of the desire for secrecy by Friedman, for a very long time nobody outside his team was aware of this transliteration exercise or the alphabet they used.
The Friedman transliteration was never meant to be a complete transliteration of all text in the MS. They decided to concentrate on the linear text written in paragraphs, and not to bother with the complicated diagrams with labels and text written in circles. This is very clear from handwritten annotatations made on the source copies saying "omit punch" or "punch just this".
The FSG transliteration alphabet uses capital letters and numbers. It has a rather unusual method (by later standards) for transliterating the 'intruding gallows', namely by using a dedicated symbol (Z) for the pedestal ().
The FSG transliteration effort is described in detail in Reeds (1995) (4). A printout of the transliteration was discovered by Jim Reeds in the above-mentioned Marshall library, and together with Jacques Guy he entered it in computer readable form. The resulting file is mirrored here. This transliteration is not complete for the reasons mentioned above. It is one of the five main transliterations of the Voynich MS that is used at this site, and will be reffered to with the two-letter code FG.
In 1976 Prof. William R. Bennett of Yale University published a book on the use of the computer to analyse certain properties of language and text (5). In this book, he dedicated a chapter to an analysis of the Voynich MS text, and for this purpose he needed a transliteration alphabet. Bennett's alphabet has not been used outside of this publication. The transliteration was made from photographs and stored on paper tape. As reported by Brumbaugh (6), Bennett was assisted in his Voynich MS analysis by Jonina Duker, who was then a sophomore student (7).
Roughly at the same time, the cryptanalist Prescott Currier started a major transliteration effort, using an alphabet he designed independently. This alphabet uses the capital letters A-Z and the numbers 0-9 (i.e. all 36). It does not represent some characters which the FSG alphabet does, and it uses single characters for what appear to be composite characters in the MS. When Currier presented his findings at the 1976 Voynich MS symposium, Mary D'Imperio suggested that it would be important that all researchers use a unified alphabet. She had also started transliterating parts of the MS using her own alphabet, which she abandoned in favour of Currier's, and the two files were merged. The combined transliteration of Currier and D'Imperio, and the transliteration alphabet designed by Currier, have been used well into the 1990's, also in the earliest years of the internet. This is the second main transliteration used at this site, and in the following it will be referred to by the two-letter code CD.
Table 1 shows the three above-mentioned alphabets together.
| Char | Bennett | FSG | Currier | Char | Bennett | FSG | Currier | |
|---|---|---|---|---|---|---|---|---|
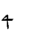 |
D | 4 | 4 | 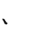 |
I | I | I | |
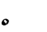 |
O | O | O | 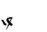 |
IL | IE | G | |
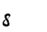 |
S | 8 | 8 | 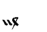 |
IIL | IIE | H | |
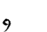 |
G | G | 9 | 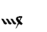 |
IIIL | IIIE | 1 | |
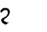 |
Z | 2 | 2 | 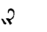 |
IQ | IR | T | |
 |
L | E | E | 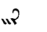 |
IIQ | IIR | U | |
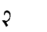 |
Q | R | R | 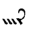 |
IIIQ | IIIR | 0 | |
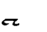 |
CT | T | S |  |
U | L | D | |
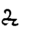 |
ET | S | Z | 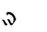 |
N | N (*) | N | |
 |
H | H | P | 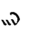 |
M | M (*) | M | |
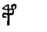 |
P | P | B | 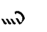 |
IM | IIIL | 3 | |
 |
K | D | F | 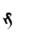 |
K | J | ||
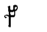 |
F | F | V | 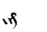 |
IK | K | ||
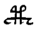 |
CHT | HZ | Q | 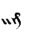 |
IIK | L | ||
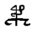 |
CPT | PZ | W | 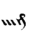 |
IIIK | 5 | ||
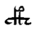 |
CKT | DZ | X | 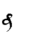 |
(6) | 6 | ||
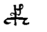 |
CFT | FZ | Y | 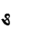 |
(7) | 7 | ||
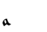 |
A | A | A |  |
Y | Y | (n) | |
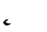 |
C | C | C | 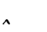 |
V | V | (v) |
Table 1: definition of the main historic alphabets
(*) Note: Tiltman used the FSG alphabet, but instead of N and M wrote IL and IIL.
One thing that immediately appears from this table is that the various researchers did not agree on what constitutes a single character in the Voynich MS text.
Later, Jim Reeds showed that many characters in the Voynich MS cannot be represented exactly by any
of the existing alphabets. There are some 'rare' characters, and in addition there are what appear
to be ligatures of several characters. These characters have traditionally been called 'weirdoes',
though here I will use the term 'rare characters'. Jim Reeds produced a document with an overview
of these rare characters, calling them 'X1' to 'X128'. An excerpt of this little known document is
shown below.
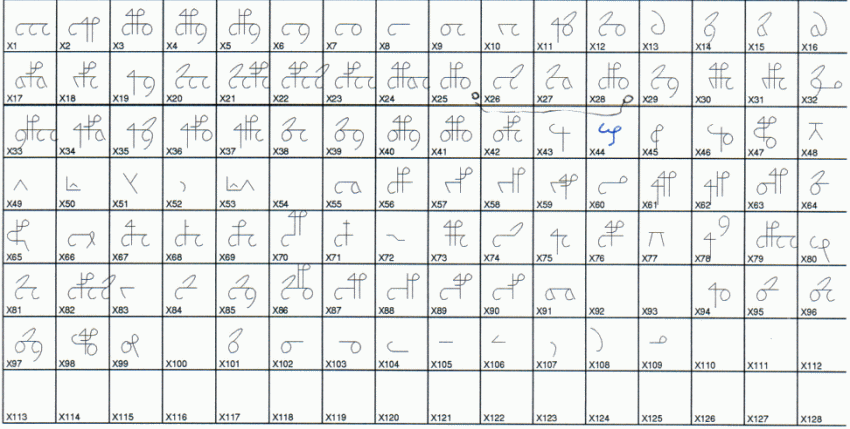
Table 2: early identification of rare characters in the MS
With the emergence of the "World Wide Web" and the start of the Voynich mailing list, transliteration of the parts that were still missing from Currier's and D'Imperio's efforts was continued using Currier's alphabet. A number of characters using lower case were added to this alphabet. These are already included (in parentheses) in Table 1. As part of this effort, a file format for this transliteration file was adopted, about which more will be said further below.
In parellel to this, a completely new type of transliteration alphabet was designed:
The 'Frogguy' transliteration alphabet was designed by Jacques Guy in 1991. It uses lower-case characters, numbers and diacritical marks. Rather than representing complete characters, it represents the 'strokes' or minims of the script of the Voynich MS. As a result of this approach, it creates a reasonably close similarity between the script and the transliterated text. At the same time, some characters in the MS which may be assumed to be a single character are represented by several using this alphabet. By its nature, it is the first alphabet that allows to properly represent many of the ligatured characters that were mentioned above. Jacques Guy also introduced the so-called 'capitalisation rule' which means that a character that is connected to the following one should be represented by a capital letter. The Frogguy transliteration alphabet and its use are explained in great in a locally preserved copy of Jacques' tuturial or alternatively in a shorter set of linked images. It may be of interest to show an example of this alphabet:
8aiiv 4oqpc89 8a2 octox osa2o2
An additional important contribution from Jacques Guy was a tool that allowed translation of transliteration files from one alphabet to another. This tool was called 'bitrans', was written in Pascal and ran in DOS. It could handle complex translation rules, such as needed for the Currier alphabet, where, for example, the translation of the character depends on context.
The Frogguy alphabet is the closest in appearance to the Voynich MS text, and it solves the main inconsistency of the Currier alphabet, namely that Currier synthesised strings of consecutive characters into single characters, while this was not done for strings of consecutive characters (8). However, it has a distinct disadvantage in that it is not very well suited for the type of numerical analysis mentioned at the top of this page, primarily because of its frequent use of the apostrophe, and to a lesser extent the mixture of letters and numbers. No signficant transliterations have been made using this alphabet.
When Gabriel Landini and myself embarked on a new transliteration of the MS, a project that we named "EVMT" at the time, we decided that a new alphabet, but one based on the principles of Frogguy, would be needed.
EVA originally stood for European Voynich Alphabet, but later became 'Extensible Voynich Alphabet'. It was designed to be similar to Frogguy, but to use only alphabetical characters. It was designed by Gabriel Landini and myself with important contributions and suggestions from Jacques Guy. Its design was part of a larger scheme which included:
To achieve this, we heavily relied on the above-mentioned 'bitrans'.
'Basic Eva' is the set of lower case characters that was identified, and 'Extended Eva' includes the representation of all types of rare characters. The basic Eva alphabet was chosen such that the transliterated text is almost pronouncible. This excellent idea from Gabriel was not to be able to 'speak Voynichese', but to make it very easy for the human brain to recognise and remember transliterated words.
The rare characters can be classified into three categories:
These were all identified in the course of the transliteration exercise, which was based on two documents: the Petersen handwritten copy of the MS already mentioned above (see note 3), and the Yale "copyflo" (11). As it turned out, there were three single characters that might be called unusual because they did not appear in any of the previously defined transliteration alphabets, but which occurred several times in the MS. These three characters: , and were assigned their own 'Basic Eva' letter (b, u and z respectively). The table of Basic Eva is included here:
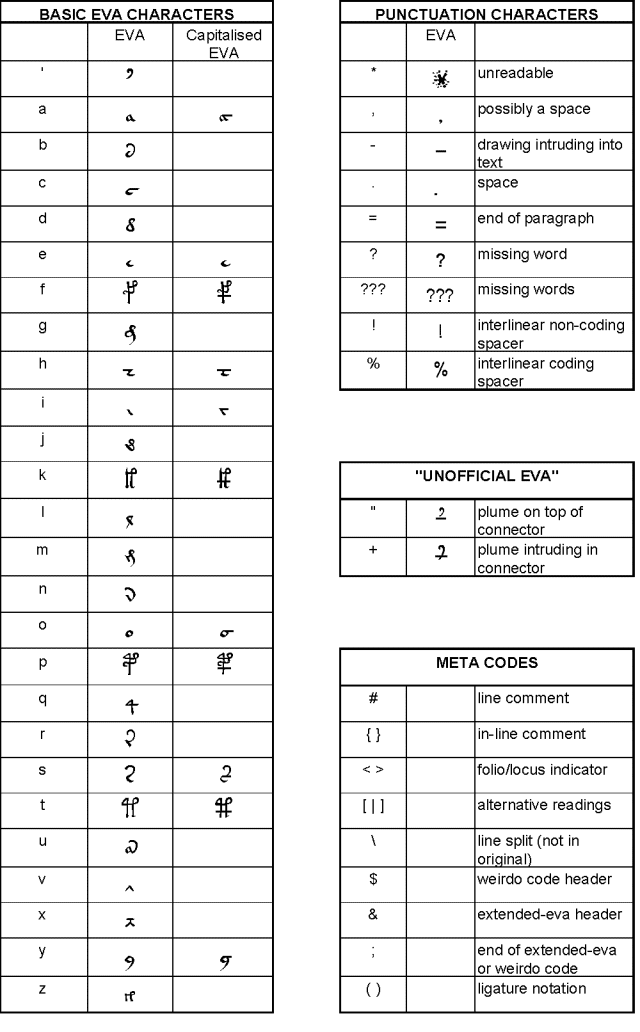
Table 3: definition of 'Basic Eva'
What appears from this table is that the characters and that have typically been considered units, and transliterated as N and M in both FSG and Currier, are transliterated in Eva as "in" and "iin". It is very important to point out that Eva is not attempting to identify semantic units in the text. It simply represents in an electronic form the shapes that are seen in the MS. It is left to a later step by analysts to decide which combinations should be seen as units. There is probably no right answer to this question, and the problems how to transliterate these strings of minims is addressed in a dedicated area.
| Strings of i's |
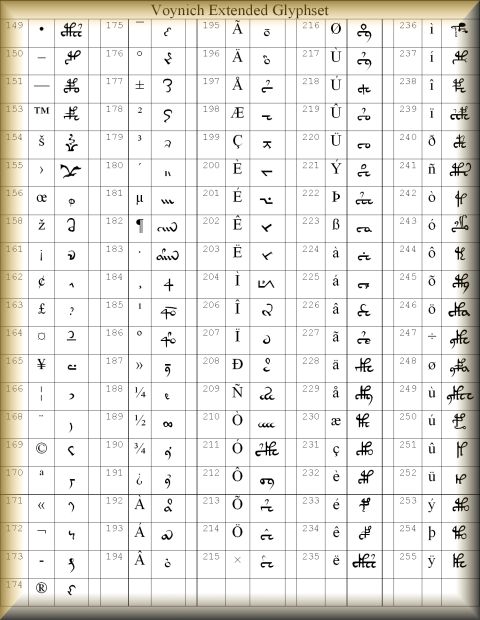
While defining the alphabet, individual rare characters, or rare parts of ligatures, were assigned a 'high ASCII' code, and the way to include them into transliteration files is defined as follows: @185; for ascii code 185 (12). Table 4 shows all such rare characters addording to the latest version of the complete definition (13).
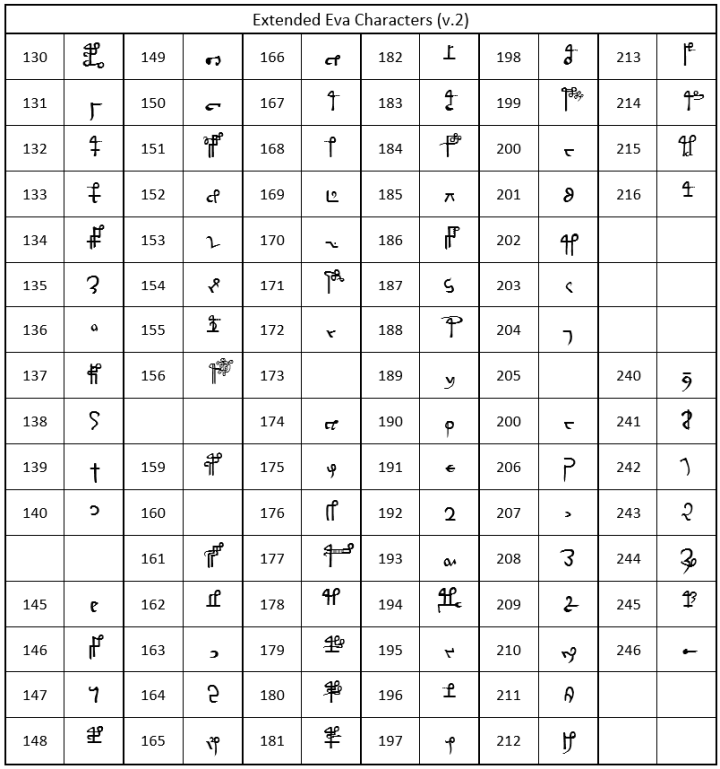
Table 4: the 'Extended Eva' character set
This table has been re-drawn using the latest Eva-2 font. A full explanation by Gabriel Landini may be found here: link to Eva-2 reference (2025).
Ligatures of characters may be represented in two ways. The first is the previously mentioned capitalisation rule introduced already by Jacques Guy. As Table 3 with the definition of basic Eva shows, this method allows an accurate representation of the text using the Eva True Type font. A capitalised character always connects to the next one. In addition, there are the following special cases:
Often, the characters Sh, cTh, cKh, cPh and cFh are simply written as sh, cth, ckh, sph and cfh respectively. This is more convenient, but it has the result that their rendition in the True Type Font is sub-optimal.
The second way to indicate ligatures in transliteration files, which is more intuitive for the human reader, is to enclose the connected characters in curly brackets (14). Table 5 shows examples of this.
| EVA | Capitalised EVA | Using TTF |
|---|---|---|
| {ao} | Ao | |
| {cthh}ey | cTHhey | |
| {yk} | Yk | |
| {c@245;h}y | c@245;hy | |
Table 5: use of ligatures and the capitalisation rule
The Eva alphabet, primarily in its basic form, found great reception in the community, and it was used by the Japanese Takeshi Takahashi to produce a new transliteration, also based on the Yale "copyflo" (see note 11), which was the first that could be considered essentially complete. He used 'capitalised Eva' to represent all benched or pedestalled characters, e.g. 'Sh' for . He has also updated his transliteration over time, based on reports from users. This is the third main transliteration at this site, and it is referred to by the two-letter code TT. It is published by Takeshi at his web site (for which see the table with links near the bottom of this page. Alternative forms derived from this are available in several places, see for example the following section.
Based on an initial effort by Jim Reeds, Gabriel Landini collected the important older transliterations mentioned above into a single interlinear file, meaning that they were presented together line by line. They were all converted into Eva, since this conversion is consistent and reversible, as mentioned above.
The brazilian Jorge Stolfi took this interlinear file and put a very significant effort into improving it, adding further transliterations. This included the complete transliteration of Takeshi Takahashi (status of 1999), where he converted the capitalised Eva to lower case. He also added his own transliterations and partial transliterations from several others, for example John Grove. As a result, this interlinear file has become the de facto source for transliteration data. In the following, it will be referred to as the Landini-Stolfi Interlinear file, with the abbreviation LSI.
It includes in particular the above-mentioned version of the Takeshi Takahashi transliteration, in its version of 1999. This copy of the Takahashi transliteration will be referred to with the two-letter code IT.
The above-mentioned EVMT project was partially completed, and led to two complete, but different transliterations. Alignment of the two versions was started, but not completed. The resulting files, which may be referred to as LZ, were never published.
At a later stage, and as will be explained further below, my own part of this transliteration has been gradually improved, and is now publicly available. This is the fourth main transliteration used at this site, and it is referred to with the two-letter code ZL. The character 'L' acknowledges the important influence of Gabriel Landini in creating this transliteration.
A few years later, Glen Claston, who referred to himself as "GC", embarked on a complete transliteration of the Voynich MS and devised a transliteration alphabet which he called Voynich 101 (here v101 for short). The v101 alphabet was designed to keep stroke combinations that appeared to him to be single signs as single characters. Furthermore, it distinguishes between several variants of characters that were considered to be one and the same in all previous alphabets. He transliterated the entire text of the Voynich MS using this alphabet. Following is his definition of the alphabet, and allocation to ASCII values.
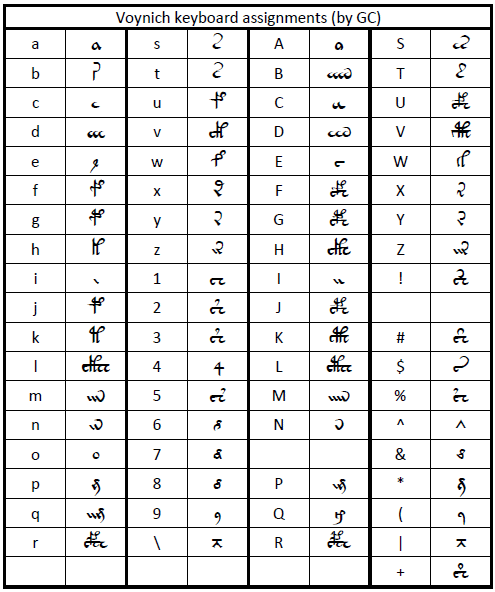
Table 6: the v101 basic character set
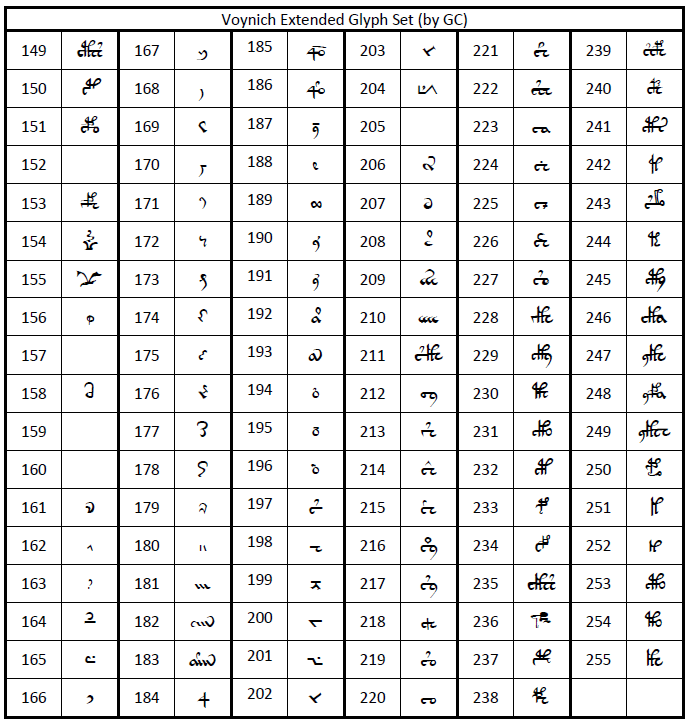
Table 7: the v101 extended character set
These tables have been re-drawn using the v101 font. The original tables by GC may be found here: IMG: v101 keyboard assignments , IMG: v101 extended glyphset. (15)
Also for the v101 alphabet a True Type font has been designed, and like the Eva font it allows high-quality rendition of the Voynich MS text in electronic documents (HTML, Word). Also this font can be downloaded at the site map. This is the fifth main transliteration used at the site, and in the following, it will be indicated by the two-letter code GC.
Around the year 2017, I decided to review the achievements and problem areas, and to embark on a gradual activity to improve the general status of Voynich MS transliteration data. In the following, I will fast forward through the work that has been done up to present. Links to more detailed explanations are provided.
Several independent transliterations of the Voynich MS are available. Among the ones listed above there are a few that are almost complete:
Transliteration of the Voynich MS is particularly difficult, because one cannot read the text. One has no help from context. The biggest problem is to decide whether two almost-similar-looking written shapes are two different ones, or two representations of the same one, where the variation is just caused by handwriting variations. While transliterating, one is continually forced to make such decisions, and it is unavoidable that these are subjective.
A similar problem exists in deciding about word spaces. Sometimes, characters are offset just a bit and it is hard to decide whether there is a space or not. Traditionally, word spaces have been indicated by a period (.) in transliteration files, while whitespace is irrelevant and used occasionally to improve the layout. Even the introduction of the comma to represent an uncertain space does not completely resolve this problem.
One way out of both these problems would be to have these decision made more objectively, i.e. by a piece of software (OCR) but it will take a bit more time before we can do this.
A second general problem is the lack of standards. As mentioned above, the transliteration files all have rather significant differences in format. There is no place where they are all collected together. Of the interlinear file there are also several versions. Takeshi Takahashi's transliteration is represented in HTML format, separated into individual web pages for each MS page. This makes it very suitable for browsing, but less for text processing.
Until the year 2017 it was impossible to present the "GC" transliteration in any of the standard formats, because many of the symbols that have a special meaning for annotation in the "LSI" (and the "LZ") file are representations of Voynich MS text characters in the "GC" transliteration. A solution to this problem had to be found.
Finally, it is almost always impossible to repeat analyses done by others since one doesn't know which data they used, and there isn't really any clear way how they could have specified it. The file format(s) used nowadays are far removed from modern representation standards. Already more than a decade ago, Rafał Prinke suggested the use of TEI (Text Encoding Initiative) but it never took off. There are a few more comments about this general topic on the final page of this site, and a more detailed description of the problem and its resolution is provided on a separate page:
| Next-generation transliteration of the text |
For analysis of the various Voynich MS text transliterations, it is highly desirable that these transliterations are contained in files with a well-defined (standardised) format. Such files should be 'annotated', meaning that they include so-called metadata, which is not the text itself, but information about the text. This metadata should indicate, for example, for each particular piece of text on which folio or page it is located, and where it is on the page. This location information was called the locus, a term that I shall continue to use. Additional relevant information about the pages or the text may be included. Analysis software should be able to either interpret this information or to ignore it.
Closest to a standard was the format of the Stolfi-Landini interlinear file, but this did not allow representation of the GC transliteration file. Still, it was used as the basis for the new standard. As a first step, and as mentioned already above, I took my own part of the EVMT transliteration effort, as one of the inputs to this process, in order to also make it publicly available. This activity, which is described here in considerable detail, was completed in three stages:
In this exercise, I included the 'IT' version of Takeshi Takahashi's transliteration, i.e. the version included in the LSI file, rather than the 'TT' version which was difficult to access. Stage 2 was a complicated process of comparing the transliteration files with each other and with the manuscript images, in order to consolidate what are the different text items, and in which order they should be presented. In stage 3, especially the v101 alphabet caused some clashes with symbols used for annotation in the LSI file, which had to be resolved.
The result of this exercise was the definition of a new format, which I have called IVTFF (Intermediate Voynich Transliteration File Format). The complete format description (version 2.0 of February 2023) is presented in this PDF document. The description of the previous version (version 1.7 of April 2020) is still preserved on a page with some legacy items.
Some of the main features of this format are:
The five main files (FSG, Currier/D'Imperio, Takahashi, Zandbergen-Landini and Claston) have all been converted to the new format, and they can be retrieved through links provided in a table near the bottom of this page, together with later additions which will be described in the following.
To pre-process all files in IVTFF format, a tool called IVTT is available. This tool can remove any combination of this metadata, but also select/delete parts of the text based on any combination of this metadata.
| Voynich Transliteration Tool |
Having all transliterations in a single standard format is clearly a great advantage, but it is still cumbersome, if not impossible, to compare the transliterated text contained in any two files in detail. For that, it would be helpful if they were all represented in the same transliteration alphabet. This principle was already explored on the parallel page with special topics.
I therefore decided to go ahead and define a Super Transliteration Alphabet, a superset of existing alphabets. The concept is explained by the following figure.
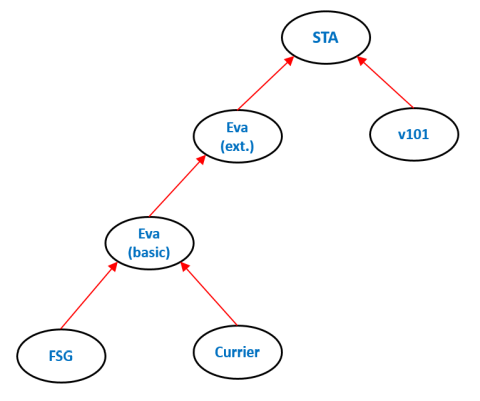
Figure 1: the hierarchical relationship between transliteration alphabets
It shows the dependencies of all main transliteration alphabets that are discussed at this site. The arrows both mean: "is based on" and "fully includes", in the sense that the 'higher' alphabet can fully represent texts expressed in the 'lower' alphabet. In the opposite direction this is generally not the case. The figure shows that it is sufficient to make a superset of Extended Eva and v101, as this automatically captures all other alphabets.
The process of creating this superset is explained in considerable detail on a dedicated page. This work was first presented at the 2022 Voynich MS Conference, as the first keynote talk on 30 November: "Transliteration of the Voynich MS text" (17).
The first decision was to make this superset a synthetic alphabet, similar to Currier or v101. This was done to avoid making too many subjective decisions related to the v101 alpabet. Since both Eva and v101 have of the order of 200 characters, the combination would certainly have even more. A single character will not be enough to represent each character in this new alphabet, so it was decided to represent all Voynich characters in STA by two Ascii characters. For this, all characters in the Voynich MS have been subdivided into groups, or rather 'character families'.
Characters that appear similar will be part of the same family. Families are identified by a single capital letter. The specific characters in each family will be called family members and are identified by a second character, where frequent characters are identified by a digit (1-9) and the rare ones by a lower-case character (a-z).
Both the identification of the different families, and the list of members in each family, has been achieved through an iterative process. This would have been an impossible task without a tool like the afore-mentioned 'bitrans'. As the original source code was lost, this has been recreated from scratch, and it is introduced in more detail on another page. This tool will also be of significant use for future users of the STA transliteration files.
The list of families with the most important family members is shown in this PDF document. Inevitably, there could be many other equivalent results, but some of the main reasons for this design stem from the Voynich MS text complications mentioned before. Much more information about these aspects is provided on the dedicated page.
The detailed STA definition (after 16 intermediate versions) is provided in this PDF document. An example of Voynich MS text expressed in STA is included in Figure 2. The top row includes a short line of writing that was taken from the fifth line of f36v.

Figure 2: an example of a transliteration in STA
The second row shows the representation of this line in five different original transliterations, using their 'native' alphabets, but already represented in the IVTFF file format. In the bottom row all text has been converted to the STA transliteration alphabet. Here, grey boxes indicate the remaining differences between the various transliterations. This demonstrates two aspects. The first is, that this transliteration is not suitable for human reading, but only for computer processing. The second is, that transliterations will tend to be consistent in the choice of character family, but mostly differ in the choice of family member for each character.
In 2023, while working on alignment of the two most complete and accurate transliterations: ZL and v101, in order to create some kind of optimal combination, I realised that for this application an analytical 'super'-alphabet would be more appropriate. Since 'bitrans' allows an easy definition of new alphabets, it was decided to set up this 'analytical alignment alphabet', or 'aaa', specifically for this purpose.
To do this, it was not necessary to go back to the definitions of Eva and v101. Instead, it could be derived directly from STA. Also, it was not necessary to include the entire definition of STA, but it could be based on a reduced set (197 out of 299 total STA codes). Similarly to Frogguy, the alphabet represents the strokes or minims of the writing in the MS.
All details are provided on a dedicated page. aaa characters are also subdivided into families, and are represented by a lower-case character followed by a single digit. Due to its verbosity, transliterations using aaa tend to be quite long. They are, however, reasonably easy to understand. As an example, following is the transliteration of in STA and aaa. The colon (:) used in aaa indicates that the two minims are connected to each other.
B1 A3 G1 d0 a0 i0 i0 i0:b0
Using this new alphabet it was possible to create the above-mentioned combined transliteration of ZL and GC in a mostly automated manner. Details are included on this page.
This will henceforth be referred to as the 'Reference Transliteration', with two-letter code 'RF'. It was not primarily intended to be most accurate in the identification of the individual characters (which in any case cannot be achieved by an automated comparison), but I consider it the most reliable in that respect. Its main purpose is indeed to be a reference, which should first of all cover all characters in the text in terms of STA codes. Other transliterations can be compared to it (using STA or aaa).
Following are links to some original transliteration resources that are known to me, and to the new copies in IVTFF format. The most recent format version is 2.0. Links to files in the previous format version (1.7) will continue to be provided in this table for a limited period of time. The reference transliteration is also inclduded using code 'RF'.
For some years these versions have not changed, but in 2025 a few mistakes were fixed at the same time, leading to updates to some of the files, namely:
| Code | Description | Alphabet | Original | IVTFF 2.0 | IVTFF 1.7 | (N) |
|---|---|---|---|---|---|---|
| FG | A copy of the FSG transliteration, created by Friedman's First Study Group, in the format prepared by Jim Reeds and Jacques Guy. | FSG | (local copy) | v. 2a | v. 1e | (20) |
| CD | The original transliteration of D'Imperio and Currier | Currier | (local copy) | v. 2a | v. 1a | (21) |
| 'Vnow' | The updated version of the C-D transliteration, made during the earliest years of the Voynich MS mailing list. | Currier | (local copy) | N. av. | N. av. | (22) |
| TT | The original transliteration by Takeshi Takahashi. | Eva | At a >>set of separate pages at his web site. | N. av. | N. av. | |
| IT | The converted transliteration by Takeshi Takahashi that is included in the Landini-Stolfi interlinear file. | Eva-T | See "LSI" below. | v. 2a | v. 1a | (23) |
| VT | The transliteration (from LSI but mainly by Takeshi Takahashi) that is included in the Voyinch MS browser at voynichese.com. | Eva-T | >>www.voynichese.com | v. 0e | N. av. | (24) |
| 'LSI' | The Landini-Stolfi Interlinear file | Eva-T | At a >>page at Stolfi's site with links to the file in various compressed formats. | N. av. | beta | |
| ZL | The "Zandbergen" part of the LZ transliteration effort. | Eva | - | v. 3b | v. 2b | (25) |
| GC | The v101 transliteration file. | v101 | Local copy. | v. 2a | v. 1b | (26) |
| RF | A "Reference" transliteration. | (Eva) | Uses STA1. |
v. 1b full basic |
N. av. | (27) |
Table 8: links to the main transliteration files
Older (legacy) versions are still available here.
A table with links to transliteration files using the STA1 alphabet is provided here.
Table 9 summarises some of the properties of those transliteration files that are available in the IVTFF format, with some explanatory notes below the table.
| Item | CD | FG | IT | ZL | GC | RF |
|---|---|---|---|---|---|---|
| Version | 2a | 2a | 2a | 3b | 2a | 1b |
| Loci | 2196 | 4060 | 5215 | 5385 | 5367 | 5385 |
| Paragraphs | 236 | 734 | 772 | 740 | 775 | - |
| Long words | 16,258 | 33,332 | 37,919 | 36,278 | 38,242 | 37,848 |
| Characters | 65,167 | 135,568 | 155,292 | 157,304 | 157,096 | 157,254 |
| Alternative readings | - | - | - | Y | - | - |
| Uncertain spaces | - | (*) | - | Y | Y | Y |
| Drawing instrusions | Y | - | Y | Y | - | Y |
| High Ascii codes | - | - | - | Y | Y | Y |
Table 9: some properties of the main transliteration files
In this table, "long words" is the number of words in case uncertain spaces are not counted.
The IT and GC files still include the spurious label on f89v2 (see note 18).
Due to the differences in the three nearly complete transliterations (IT, ZL, GC), no consolidated paragraph count exists today, so these have not (yet) been included in the Reference transliteration.
The number of characters is based on the STA1 alphabet. Unknown characters (STA code Z1) are counted as 1. Sequences of unknown characters are also counted as 1.
The FSG file only has very few alternative readings, for cases where two punched records for the same locus exist.
The RF file was previously (version 1a) only provided in basic Eva, and did not have high Ascii codes. Version 1b is additionally expressed in extended (full) Eva, which has many.
The >>Voynich Information Browser by Elias Schwerdtfeger allows extraction of individual transliterations from the "LSI" file, with many useful options (to be checked).
|
|
|
|
|
|
|
|
|
|
{kind=link}
{kind=link}