



|
|
|
|
|
In 1976 Prescott Currier proposed that the pages of the Voynich Manuscript were written in two different 'languages', which he called "A" and "B" (1). He made clear that these do not necessarily represent two different languages, but they are a reflection of different statistical properties of the text.
At the same time, he also identified two (or more) different handwriting styles in the MS, and for the last few decades the terms "Currier language" and "Currier hand" have been part of the terminology used by many people studying the text of the Voynich MS. Only as recently as 2020, the handwriting identification by Currier was superseded by that of the medievalist Lisa Fagin Davis, which was already introduced here. (2) Given that Lisa is a palaeographer, and Currier may have been at best an amateur in that area, we are justified to now ignore Currier's original classification and concentrate on the newer one.
His language identification, which is briefly summarised here, still stands, but numerous attempts have been made to improve on it or extend it. Two pages at this web site, "Ref-1" and "Ref-2", provide examples of such attempts. This work has been on-going, and the present page provides a first result.
Note: this is an update made on 30 April 2024 of the first version that appeared 20 April 2024. This fixes the sub-optimal classification of frequency of words starting with Eva-q.
It has to be understood that all text statistics will be affected by errors in the transliteration. These are still very difficult to quantify. The most uncertain aspect is related to word spaces, and consequently statistics related to full words are most vulnerable. At the same time, textual variations may be partially due to the scribe. This still requires further analysis. A more detailed publication of the material summarised on the present page is in preparation (3).
A first shortcoming in Currier's identification is that he did not provide a classification for all pages in the MS (4). "Ref-2" (mentioned above) already indicates that the pages not classified by him may possibly represent some intermediate language (or range of languages).
A second more subjective shortcoming is, that some of his criteria are more of a qualitative nature. A more precise criterium to split between his two languages was identified over the years, namely the presence of the bigram (Eva: "ed"). This is essentially non-existent in all A-language pages, and very frequent on all B-language pages.
The aim of the present exercise is to find a 'language' classification for all pages in the MS, based on quantitative criteria. In this, we also want to reflect additional variations of the languages, which we may call dialects, similarly to what was already observed in "Ref-1" and "Ref-2".
To achieve this, the presently most reliable transliteration is used, namely the RF transliteration included in this table (version 1a, in basic Eva). Based on the earlier observation, that pages with similar illustrations also tend to exhibit similar dialects, this text has been split into several groups. Numerous statistics have been collected for the complete text, and for these groups. The groups are listed below. Note that the combination of all groups is not the complete text. In particular, text-only pages that are part of a particular type of illustration are not included (5).
| Part ID | Description | Nr of words |
|---|---|---|
| F | The complete text | 38,529 |
| A | Text on herbal pages classified by Currier as A-language, in the early part of the Manuscript (before quire 9) | 6926 |
| P | All other pages classified by Currier as A-language, mainly with pharmaceutical illustrations (but excluding the labels), plus the herbal-A pages in quires 15 and 17 | 3236 |
| M | The collection of labels on pages with pharmaceutical illustrations | 211 |
| C | Text on pages with astronomical or cosmological illustrations, but not the zodiac, and excluding the labels | 2736 |
| N | All labels in the MS that are not part of groups L or M | 589 |
| Z | The circular texts on the zodiac pages | 925 |
| L | The labels on the zodiac pages | 343 |
| R | The text on f58r and f58v | 742 |
| S | The text on three bifolios in the recipes section / quire 20: folios 103, 107, 108, 111, 112, 116(r) | 5270 |
| T | The text on three bifolios in the recipes section / quire 20: folios 104, 105, 106, 113, 114, 115 | 5536 |
| H | Text on herbal pages classified by Currier as B-language | 3414 |
| B | Text on pages with biological / balneological illustrations, excluding the labels | 6835 |
The herbal pages classified by Currier as A language, that appear near the pharmaceutical pages towards the end of the MS, have been grouped together with the pharmceutical pages, because it was already known from earlier experiments that their text properties are more similar to those of the pharmaceutical pages.
The final classification may not necessarily be along the above separation. That decision will will be made once we have collected a sufficient number of statistics. Initially, this will be done on the basis of bifolios, because there is still a general sense that entire bifolios represent a unit of some sort. Furthermore, bifolios provide more text than individual pages, allowing for a more reliable identificaton.
Following that, individual folios and individual pages will be classified and this is where we will see if the consistency per bifolio holds. Also in Lisa Fagin Davis' scribal hand identifications, a few exceptions were found. During this analysis, these scribal hand identifications will not be taken into account. If there is any correlation beteen the hands and the dialects, we will find out at the end.
With respect to the highest-level divider mentioned above, namely the presence of the bigram (Eva) "ed", for the entire MS this appears on average in 13.3% of all words. There are four groups where the count is higher, namely the known B-language groups S, T, H and B (stars/recipes, herbal-B and biological/balneological). These numbers are collected in a table below.
The lowest score in this 'B' group is 16.5% while the highest score outside this group is 9.3%. We may therefore put a 'dividing criterium' at 12.5%.
| Part ID | Brief description | % "ed" | Currier | New |
|---|---|---|---|---|
| F | Full text | 13.26 | - | - |
| A | Early Herbal-A | 0.10 | A | A |
| P | Pharma text and late Herbal-A | 0.56 | A | A |
| M | Pharma labels | 0.47 | A | A |
| C | Cosmo text | 8.22 | - | C |
| N | Other labels | 9.34 | - | C |
| Z | Zodiac text | 6.49 | - | C |
| L | Zodiac labels | 5.25 | - | C |
| R | f58 r+v | 0.94 | A | A |
| S | quire 20 part 1 | 17.69 | B | B |
| T | quire 20 part 2 | 20.61 | B | B |
| H | Herbal-B | 16.46 | B | B |
| B | Bio text | 27.94 | B | B |
The groups that are below 12.5% can also be split into two parts. The 'traditional' A-language pages (groups A, P, M, R) range between 0.1% and 0.9%. The other four (groups C, N, Z, L) have 5.3% to 9.3%. We may therefore put a second 'dividing criterium' at 3% . Below this criterium we have Currier's A pages, and the remainder are the astrological/cosmological and zodiac pages, which we may now classify as language "C" (for Cosmological). This classification has been included in the above Table.
With this, I would like to introduce the "RZ" language identification, which consists of three main languages and a further classification into variants or dialects. They will be identified as the language letter (capital A, B, C), followed by further symbols depending on the detailed classification, which is explored in the following.
Following is a list of properties that have been identified in the past, by Currier, by myself, or by others as indicated, that may lead to additional classification criteria.
In Eva, these words are "chol" () and "chor" (). This represents Currier's second criterium, where he states that these are very frequent in "A" and low-frequency in "B". Related to this, Jacques Guy published a paper in Cryptologia (6), where he found that a count of letter frequencies shows that letter occurs systematically in Language A where letter does in Language B. This led to further insights (only partially reported in "Ref-1") related to an apparent sequence of variations (Eva:) chol, cheol, cheody, chedy. In particular it was found that the bigram "eo" is very frequent in the pharma pages, but not in the herbal pages.
On average, this bigram appears in 8.7% of all words in the MS. Exceptions on the high end are in the pharmaceutical pages (25%), but not so much in the labels, and in the zodiac pages, also in the labels. We may put a cut-off criterium at 16.7% (1/6) to positively identify a dialect, which exists for the A and C languages. On the lower end, the "eo" bigram is low in the biological pages, where, in particular, the trigram "eod" appears in only one of 6000+ words. This suggests a clear identifier for a 'Bio' dialect.
Tiltman's word split into roots and suffixes was briefly discussed here. He also called his suffixes: finals, and he reported that the section of the MS that Friedman gave him to study in more detail stood out for having more frequent unattached finals. This was the so-called recipes section, or quire 20.
Among the most frequent words in the MS are "daiin" (ranked #1) and "aiin" (#3). These are an example of a root+suffix word versus an unattached final. Other unattached finals that appear very frequently are "or", "ar", "ol" and "al", but the distribution of all these words varies across the different sections. Also Currier lists these unattached finals as a property of his B language. Following are some of the more conspicuous examples.
It is long known that words starting with "q" are essentially always followed by "o", so when speaking about words starting "q" this is equivalent with words starting "qo". It has been observed by several people independently, that label words tend not to start with "q".
Overall, 14% of words start with "q". They are least frequent in the C-language pages, even when excluding the label words. Next are the herbal pages (both A and B), followed by pharma-A, then followed by f58 (r+v). The extreme case is biological B where almost 25% of words start with "q".
Whereas word-initial "qo" is very frequent, and so is word-final "ol", the word "qol" is quite rare. Without going into possible reasons for this, following are the main statistics.
The word appears 146 times, which represents 0.4% of all words. Six of these occurrences are in the combined herbal (A and B) and pharma sections. The vast majority are in the biological section, where it represents 1.6% of all words. A positive identifier for this dialect is achieved when it appears more often than the word "chol".
A language appears with three types of illustrations: herbal, pharma, and f58 (r+v) with a few marginal stars. The language is pharma when words including "eo" cover more than 16.7%.
The "stars" dialect (f58) stands out for having far fewer cases of the word "daiin" than the other two, yet far more cases of the word "ar". Its frequency of "eo" is clearly below the pharma limit.
The following two criteria were already mentioned:
The following 5 indicative criteria were found, but these will all need to be double-checked.
There are criteria that apply for all recipes pages, and there are those, for which the result is highly variable. The only apparently reliable criterium appears to be that the sum of the counts of the words "ar" and "al" should be greater than those of "or" plus "ol".
While the statistics for the two sets of three bifolia as in the table further above are different in several instances, there are clear indications that the separation, or the boundaries of common properties, is not necessarily along these bifolia. Given that there is abundant text on every page, each page can be analysed separately.
The following indications were found, but they need to be double-checked.
Initial experimentation with the above criteria in order to classify individual pages immediately highlighted two issues.
First, some criteria are based on a low percentage of words, and such criteria will fail for smaller groups of text, such as individual herbal A pages, or pages that mainly include labels (which are treated separately). Such criteria will be dropped as part of a first (still experimental) classification. In particular, all criteria for detecting a Herbal-B dialect had to be dropped, at least for the time being.
Secondly, the old observation after Currier's work, that all four (or more) pages in a bifolio tend to be classified the same, still largely holds, but there are plenty of exceptions. Therefore, the classification is made for pages, for folios and for bifolios, and reported for all three when discussing any page. See below ('Implementation') for an example.
As for the groups, in the counts for pages, folios and bifolios labels are excluded. These will be treated separately, but this has not yet been done.
Based on this, we may define the following (initial) language and dialect codes:
Furthermore, the code may have a post-fixed + or - as follows:
The low limit for assigning a minus sign is because the herbal and pharma pages are scattered around 10% of words starting with "q", so a higher limit would create a lot of arbitrary cases in these areas. The chosen limit captures the truly low cases known from earlier experimentation.
The following table lists the above statistics for the various groups of pages that were listed further above.
| Part ID | Brief description | % "ed" | % "eo" | % "q-" | qol | Code |
|---|---|---|---|---|---|---|
| F | Full text | 13.26 | 8.69 | 14.00 | -218 | (B) |
| A | Early herbal-A | 0.10 | 4.89 | 9.15 | -187 | A |
| P | Pharma text and late herbal-A | 0.56 | 24.66 | 11.80 | Ae | |
| M | Pharma labels | 0.47 | 9.95 | 0.47 | A- | |
| C | Cosmo text | 8.22 | 11.95 | 5.67 | C | |
| N | Other labels | 9.34 | 4.41 | 1.70 | C- | |
| Z | Zodiac text | 6.49 | 22.38 | 1.41 | Ce- | |
| L | Zodiac labels | 5.25 | 18.37 | 0.29 | Ce- | |
| R | f58 r+v | 0.94 | 7.95 | 13.48 | A | |
| S | quire 20 part 1 | 17.69 | 11.97 | 16.83 | -19 | Bs+ |
| T | quire 20 part 2 | 20.61 | 6.21 | 17.83 | -12 | Bs+ |
| H | Herbal-B | 16.46 | 6.88 | 9.99 | -9 | B |
| B | Bio text | 27.94 | 2.62 | 24.35 | +101 | Bb+ |
Note that the column "qol" lists 'counts of "qol"' minus 'counts of "chol"', only in case there are any occurrences of "qol".
The relationship between the various dialects is shown below. The arrows connect the two dialects that are most similar to each other.
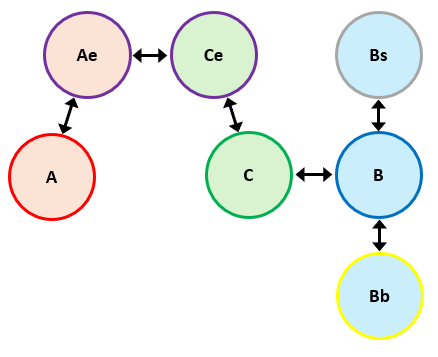
These language classifications have been added to the page descriptions found via this link.
For each page, three values are provided: one for the page itself, one for the combination of pages (including the present one) on the same folio, and one for the combination of all pages (including the present one) on the same bifolio.
Example: f17r is classified as "A", f17v as "Ae", f24r as "A" and f24v as "A-". The combination of folio f17 (r+v) is "A" and folio f24 (r+v) is also "A". The combination of all four (a single bifolio) is therefore also "A". This means that page f17v is described as:
RZ language: Ae (page) / A (folio) / A (bifolio)
In case a page has a significant number of labels, such as some astro/cosmo pages, the zodiac and the pharma pages, a separate classification for these labels will be provided in the near future (this is still under work).
It is stressed again that this is just an early iteration in a longer process, and certain improvements can already be foreseen. One aim should be to have a better criteria to decide between C and B language - the simple count of "ed" bigrams is not really adequate. For example, the "e" dialect exists in C language, but plays no role in B language. Furthermore, there are several indicators of a herbal dialect in B language that have not yet been implemented.
In the following, the term "language" refers to the highest level classifier which is just "A", "B" or "C". The term "clean dialect" is used for the full code, but without any trailing "+" or "-" sign.
The following two Tables count the number of pages and the number of words for each language and for each clean dialect. Since C is an intermediate form between languages A and B, its data will always be placed in between. The main observations from these statistics are summarised below the tables.
| Pages | Words | Wd/Pg | |
|---|---|---|---|
| A | 126 | 12,273 | 97 |
| C | 35 | 6030 | 172 |
| B | 64 | 19,043 | 298 |
| Tot | 225 | 37,346 | 166 |
| Pages | Words | Wd/Pg | |
|---|---|---|---|
| A | 97 | 8990 | 93 |
| Ae | 29 | 3283 | 113 |
| C | 23 | 4120 | 179 |
| Ce | 11 | 1474 | 134 |
| Cb | 1 | 436 | 436 |
| B | 26 | 5636 | 217 |
| Bb | 19 | 6613 | 348 |
| Bs | 19 | 6794 | 358 |
| Tot | 225 | 37,346 | 166 |
We may also compare the word-initial "q" counts against the language, and this is done in the Table below.
| - | (none) | + | Tot | |
|---|---|---|---|---|
| A | 17 | 94 | 15 | 126 |
| C | 12 | 20 | 3 | 35 |
| B | 2 | 30 | 32 | 64 |
| Tot | 31 | 144 | 50 | 225 |
It is of particular interest to see if there is any relationship between the languages, dialects and the scribal hands (1-5). The following Table counts the number of pages for each combination of language and scribal hand. The main observations from these statistics are summarised below the table.
| A | C | B | Sum | |
|---|---|---|---|---|
| 1 | 112 | 1 | 0 | 113 |
| 2 | 0 | 11 | 35 | 46 |
| 3 | 2 | 9 | 21 | 32 |
| 4 | 12 | 13 | 2 | 27 |
| 5 | 0 | 1 | 6 | 7 |
| Tot | 126 | 35 | 64 | 225 |
It is also of interest to see how the pages with very low or very high initial Eva-q are subdivided over the scribes. This is shown in the following table, with some observations listed below it.
| - | (none) | + | Sum | |
|---|---|---|---|---|
| 1 | 11 | 88 | 14 | 114 |
| 2 | 1 | 23 | 22 | 46 |
| 3 | 0 | 19 | 13 | 32 |
| 4 | 18 | 9 | 0 | 27 |
| 5 | 1 | 5 | 1 | 7 |
| Tot | 31 | 144 | 50 | 225 |
It is quite intriguing to see not only that there are clear trends for the scribes in these two tables, but also that the trends in the two cases are not along the same lines. For example, scribes 1 and 5 generate opposite languages, but have the same behaviour in the case of word-initial "q". Only scribes 2 and 3 tend to show the same behaviour.
We may also make the counts of clean dialects vs scribal hands. In this, we can merge the Cb dialect in with the Bb dialect, for reasons explained above. The corresponding column is marked with an (*).
| A | Ae | C | Ce | B | Bb* | Bs | |
|---|---|---|---|---|---|---|---|
| 1 | 88 | 24 | 1 | 0 | 0 | 0 | 0 |
| 2 | 0 | 0 | 10 | 0 | 13 | 19 | 4 |
| 3 | 2 | 0 | 8 | 1 | 7 | 1 | 13 |
| 4 | 7 | 5 | 3 | 10 | 2 | 0 | 0 |
| 5 | 0 | 0 | 1 | 0 | 4 | 0 | 2 |
| Tot | 97 | 29 | 23 | 11 | 26 | 20 | 19 |
Possibly the most interesting observation here is, that scribe 3 has some output in almost all dialects. The two pages in A language are f58r and f58v, which are text-only with marginal stars, similarly to the recipes section in quire 20, which is scribe 3's main output.
|
|
|
|
|