



|
|
|
|
|
The main page related to transliteration is here. The present page has the following topics:
The main page related to text transliteration describes the presently available transliteration systems and files, and a bit of history. In order to fully understand the following discussion, the reader should be familiar with its contents.
The 'main page' shows that available transliterations are based on concepts of several decades ago. They use simple text files which allow very easy parsing by simple tools, which is convenient, but not in line with modern representation standards. It was already suggested on that page that a new generation of transliteration is due, and a similar feeling was expressed in the page describing my views. In the following this is discussed in more detail.
I should first address one potential misunderstanding: the existing transliterations are not 'bad'. Under the simple assumption that the text of the Voynich MS should be a plain text encrypted using some standard method of the 15th century, it would have been solved easily using even the earliest transliterations made by Friedman or by Currier. That this did not happen is not the fault of the transliterations, but of the assumption.
Now even though the existing tansliterations are not 'bad', there is certainly room for significant improvement.
The purpose (in my opinion) of any new transliteration is to have the best possible data available in a state-of-the-art manner, and capturing much more necessary and useful information than the present transliteration files do. This is independent of the approach selected for analysing the text.
Our primary source is the physical MS itself. This is, however, not readily accessible. What's more, even if we had some time to study it, we would not be able to do any significant text analysis, since we cannot search the text without leafing through the entire book. We therefore need to use derivatives of the original to work with.
The first level of abstraction is given by pictures of the MS. These may be analog pictures such as, for example, in the recent photo facsimiles (1). With these, we lose something, namely the interaction with the physical object, and everything that we can only observe from the original. We also gain something, namely ease of access. We can have the book at home and browse it anytime. At the same time, searching the MS is still only possible by leafing through the entire book.
Even more useful are digital images of the MS, which we may call the first derivative. With these digital images, we have a few more advantages, namely:
Our target level of abstraction consists of the electronic text transliterations, but I won't call this the second level. As will become clear in the course of this page, I would consider this the fourth level of abstraction.
In this lowest abstraction we both lose and gain enormously. What we gain is the fact that we can search the text, both manually and in automated processes, and we can generate statistics, indexes etc. What we lose may be summarised as follows:
A third problem inherent to transliterations of the Voynich MS text is a combination of the above two points: the uncertain definition of word boundaries or word spaces. The word boundary definitions are based on subjective decisions made by transcribers deriving from the layout of the text.
The main transliterations that are available do not all capture the same information. Those that have been collected in the interlinear file have some useful meta-data. This term means any descriptive data about the text, rather than the transliteration itself. These data, among others, identify the location in the MS of each transliterated piece of text, but also additional information. All transliterations in the interlinear file use the Eva transliteration alphabet, but in the 'Basic Eva' form without the special, important extensions.
The v101 transliteration by GC is likely to be the most accurate and consistent one, but this has a less standard location identification and lacks all other meta-data. It is using a different transliteration alphabet, and for both historical and practical reasons it has not been included in the interlinear file.
This last point is worth a small initial discussion. It will be addressed more fully later. In principle, there is no reason that all transliterations in the interlinear file should use the same transliteration alphabet. It should be possible to identify the alphabet used for each entry in one way or another. That Eva was used for all other ones lies in the fact that Eva was defined such that all existing transliterations could be converted to Eva without loss of information, and in a reversible manner. For that reason there was no need to maintain the original alphabets, but these alphabets can still be used. The same is not true for v101, and even a rendition into Eva using the extended characters is not possible without loss of information.
The need to generate a better transliteration was also discussed by Nick Pelling at >>this blog post with comments from several contributors. (While the name or title "EVA 2.0" is not entirely appropriate in my opinion, I suppose that this was more of a catch phrase rather than a serious proposal.)
Making a new transliteration is a very significant effort, and it is only worth doing if it really improves upon what is available now. It should preserve the advantages we have now, solve as many of the existing problems and shortcomings as possible, and bring additional advantages.
To judge the effort in making a new transliteration, it would be useful to know how many characters there are in the written text of the MS.
Do we know the answer to this very simple question? No we don't.
After one hundred years of statistical analyses, the answer to this simple question is unknown. What's worse, if four people were asked today to make a count, they would come up with five different answers.
Partly, that is understandable. Which of the transliteration files is complete? (Hint: none of them are). Furthermore, there is no agreed definition of the character set. The number of characters depends on this definition. Even if this number cannot be determined yet, it would be important that, if two people made a count based on the same assumptions, they end up with the same answer. They should be able to state their assumptions in such a way that someone else could repeat the count and come up with the same answer. Let me therefore insert an intermezzo related to standards and conventions.
Why are they important?
Standards and conventions facilitate collaboration. They allow people to exchange data and results, and for everybody to 'talk the same language'. They allow verification.
This should be completely obvious, but let me just give a small example. Imagine that two people (users 1 and 2) have made their own transliterations of part of the Voynich MS text. Now imagine that someone (user 3) wanted to compute the entropy values of these two transliterations. He has a tool to do that. He would need to read and process the two transliterations, which is easy (and reliable) if both use the same file format, following some convention. If they are not following the same convention, the work is more difficult because the tool of user 3 has to be modified to read one or the other. As a consequence it is also less reliable since there could be a bug that affects one and not the other. Next, a second person also has a tool to compute entropy. This could be used as a cross-check (verification). This only works well if there is a standard format that all developers of tools can rely on.
Do we have any, and if not, why not?
There are numerous examples of conventions related to the Voynich MS. In the days of Friedman, pages of the Voynich MS were identified with the so-called Petersen page numbers. We still find them, e.g., in Currier's paper (Table A). Nowaways, the standard way to refer to the pages in the MS is using the foliation of the MS. The latter is used in many web resources, and in the transliteration files.
Use of the Eva transliteration alphabet in discussions about the Voynich MS is an example of a de facto convention. It was not the result of a committee decision that was enforced through some document, but a personal effort of two people (Gabriel Landini and myself) that was considered useful and was generally adopted.
The naming of the various sections in the Voynich MS ("herbal", "biological", "pharmaceutical") is another example that is useful to illustrate some points. Not all people like all these terms, and as a result, different people use different names for the same thing. While, fortunately, this is irrelevant for the chances of translating the Voynich MS text, it makes communication cumbersome. The point to be made here is that conventions do not need to represent the most accurate way to name or describe things. What matters is that they are usable and that they are generally accepted.
In 'real-life' international collaboration activities, committees or bodies are set up to discuss and agree on standards and conventions, and a majority decision is made. After that, also those who had a different opinion agree to adopt the standard. This is the process that makes collaboration possible. In the world of the Voynich MS, there are no such committees, and everybody is happy to do their own thing. Progress is made by individuals who are not 'talking' but 'doing'. The Eva alphabet, the interlinear transliteration file and GC's v101 transliteration (2), the Jason Davies Voyager (3) and the text/page browser at voynichese.com (4) are excellent examples of this.
I would suggest that all improvements that can be made to the present state of Voynich MS transliteration can be classified largely into two groups:
The most frequently discussed point in this area is the question what the best transliteration alphabet should look like. A large part of the main page is devoted to describing the various historical transliteration alphabets, and some of their pros and cons. It is not certain (at least not to me) that there should be one single 'best' and commonly agreed transliteration alphabet, that should be used by everybody.
The main problem is the subjectiveness that should be removed, or at least reduced, from the
transliteration. This is a very complex issue, and in a way it comes down to the definition
of the transliteration alphabet. This is not the question whether the shape:
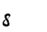
should be transcribed as "d" or "8". This is completely irrelevant. The real problem to be solved is
how to group similar-looking characters into a single transliterated character.
Looking at this problem in a very abstract manner, one could argue that in principle all characters in the MS are different, since they have been written by hand. This would of course be a completely useless way to transliterate the text, but it defines the starting point for the definition of any transliteration alphabet:
In principle, every character in the MS could be described by a small graphics file extracted from the digital images. Whether this is a good solution in practice may be seriously doubted, but at least this presents a new, even if perhaps not very practical, level of abstraction in between the digital scans and the transliterated text. It may be called the second level of abstraction.
Since automated transliteration from digital images (e.g. in an OCR process) is not yet practically possible for the Voynich MS and other handwritten documents (5), another intermediate level of abstraction could be introduced, namely that of a transliteration 'super alphabet'. This would be one that captured all subtle differences between characters, resulting in a very large 'alphabet'. How should this be defined or organised?
Without claiming that this is the only or even the best solution, I imagine such a super alphabet to be organised into 'character families'. This may be explained using Eva just for illustration purposes: there could be a family of all y-like characters, a family of all r-like characters, one of all sh-like characters etc. etc. It could consist of two identifiers for each character: the family identifier and the 'family member' identifier.
Such an alphabet would not be suited for practical statistical analyses, but it would allow researchers to define, use and experiment with their own alphabets. How one would arrive at this alphabet from the digital images is not yet clear. At least theoretically, this rendition of the text using a 'super alphabet' can be the third level of abstraction.
While a definitive Super Translitation Alphabet (STA) would be defined after a renewed transliteration effort, ndoubtedly including numerous new characters, it is already possible to define a 'reduced' version of such an alphabet as a superset of all existing transliteration alphabets. This effort has been made, and after an iterative procedure, I have defined such an alphabet, which is referred to as "STA-1" or just simply "STA". It was achieved after an iterative process.
This effort was first presented at the 2022 online Voynich MS conference (6), where the alphabet was still preliminary. Its final state is described in more detail on a dedicated page at this site.
The issues related to data storage / formats that should be resolved may be developed from the points raised above:
Eventually, and ideally, all information should be contained in an on-line database, with query tools to extract what one would need, in well-defined formats. Thus, when I wrote earlier this page, that standards like 'TEI' should be supported, I see this as an output from a query to this database.
The definition of such a database is a task that requires preparation. It should be decided which data should be included in it. Once such a database is defined, all tools and products that are available at present should be able to work with it, either directly, or from extracts of it made by standard queries. For example: any transliteration file should be an extract of it, but also tools like the Jason Davies voyager (see note 3) or the tool known as 'voynichese.com' (see note 4) could be based on this database (7).
One of the many issues to be resolved is that there is presently no standard method for identifying the exact location on a page of any text item. The Jason Davies voyager has implemented one method, and 'voynichese.com' has implemented another. The data from the latter are available at that site in the form of XML files, which is an extremely valuable resource that has hardly been used beside at its own site.
The following table summarises the abstraction levels and their relative usefulness that were introduced above.
| Level | Data | Useful? | Comment |
|---|---|---|---|
| 0 | The original MS | Limited | Not generally accessible, and useful for specialists only. |
| 1a | Original MS scans | Yes | General purpose use, suboptimal for OCR. |
| 1b | Processed MS scans | Yes | Cleaned up, possibly text-only, but same dimensions as original, for OCR. |
| 2 | Image clips of characters | Hardly | Possibly for visual comparison only. |
| 3 | Database using 'super alphabet' | Yes | Should be the source for all work. Will require an iterative process to achieve. |
| 4 | Transliteration files | Yes | Ascii text files for numerical analysis, based on a database query. |
The following bullet list includes my suggestions about what could be done on the short and intermediate term to arrive at a better transliteration database:
Of all bullet points above, the most complicated part is related to the iterative improvement of the database and 'super alphabet', which will require considerable further thought, and is clearly a longer-term objective.
It should be noted that the above database is not only useful for text analysis, but also for some aspects of handwriting analysis, e.g. text size, slant angle, line distance, maintenance of margins, etc. For these aspects, no numerical data is presently available.
At the start of the year 2023 I embarked on a medium-to-long term activity to implement all of the above. I refer to this activity as "integrated text and image processing of the Voynich MS", and documentation of this activity will gradually appear, and be referred to here and at "academia.edu".
This activity is making use of what I called 'assisted OCR' above. This is a two-step OCR process that makes use of a priori information of the text to be recognised. This a priori information is contained in a so-called 'reference transliteration', of which a first version is also already available. It is described on this page and made available for download at the main page (see table).
Step 1 of this process consists in finding the precise location of each character in the reference transliteration, and improving this transliteration in the process, by correcting for missing or superfluous characters.
Once this has been achieved, step 2 of the process consists in better identifying the characters at the established locations. While the STA alphabet is at the basis of this activity, for the OCR it is more convenient to use a stroke-based transliteration. For this purpose, also a dedicated alpabet has been defined, which I have called "aaa" (analytical alignment alphabet). Its sole purpose is to facilitate alignment of different transliterations, and alignment of a transliteration to the MS images. It is equally described on this page.
![]()
For the analysis of the various Voynich MS text transliterations, it is highly desirable that these transliterations are contained in files with a well-defined (standardised) format. Such files should be 'annotated', meaning that they include so-called metadata, which is not the text itself, but information about the text. This metadata should indicate, for example, for each particular piece of text on which folio or page it is located, and where it is on the page. In earlier days, this location information was called the "locus", a term that I shall continue to use. Additional relevant information about the pages or the text may be included. Analysis software should be able to either interpret this information or to ignore it.
In the earliest days of the internet, when the transliteration by Currier was being extended, a format was agreed for this new file. This format was extended in the course of the EVMT transliteration by Gabriel Landini and myself. It was further modified by Jorge Stolfi, and used in this final version in the main resource: the Stolfi-Landini interlinear file.
Unfortunately, the differences between the above three formats are quite significant, and the v101 transliteration file uses yet another, completely different representation. It is not particularly useful to describe any of these formats in more detail.
To achieve a new common format, the following steps have been undertaken in 2017:
Three nearly complete transliterations of the text exist, but how complete are they in reality? To answer this question, I have compared all three with each other, and with the digital images of the MS. This showed first of all that there are some inconsistencies in counting the different loci. The following table presents the total counts:
| Code | Description | Locus count |
|---|---|---|
| LZ | The Landini-Zandbergen transliteration (formerly: EVMT). | 5342 |
| LSI | The Landini-Stolfi Interlinear file | 5362 |
| GC | The v101 transliteration file by Glen Claston | 4486 |
It appeared that none of the transliterations was complete, and there are even some loci that are not included in any of them. Furthermore, there are several inconsistencies between the definition of individual loci in these files. The much lower number in the GC file is due to the fact that GC grouped many individual labels together under single loci, which he gave long descriptive names. The much smaller difference between the LZ and LSI files is related among others to the different grouping of multi-word labels. These differences are addressed in more detail in the following, in order to arrive at a common definition, where possible based on a majority, while also taking into account the older transliteration efforts initiated by Friedman and Currier.
Following are the major inconsistencies between the definition of individual loci in the main transliteration files, and the way these can be resolved.
In the oldest transliteration files (FSG, C-D), loci were simply numbered incrementally from 1, but these did not include transliterations of special items like labels, circular text etc. In the frame of the EVMT activity, where these were all included, labels were prefixed by L, circular and radial text by C and R, individual words that were not near a drawing element by S and 'blocked' text (consecutive lines that were not part of the standard paragraphs) by B.
This usage was extended by Stolfi in the LSI file, but unfortunately in quite an inconsistent manner, due to the fact that there were various different people doing the transliteration. Standard paragraph text was prefixed by P, but sometimes also P1, P2 etc if the different paragraphs could be counted easily. Thus, the first line could be P.1, P1.1 or P.1.1 depending on the page. Other codes were introduced, covering almost half the alphabet, and also some lower-case letters. L sometimes meant "label" and sometimes "left". This issue still affects online tools that extract text from the interlinear file.
A new convention, more similar to EVMT, has therefore been introduced in 2017, where the locus type is characterised by one of four main types (upper case characters), and a longer list of sub-types (second character: lower-case character or number), as follows:
| Main type | Description |
|---|---|
| P | Text in paragraphs. The second character gives more details. The 'standard' paragraph text has type P0, whereas the old 'blocked' locus type becomes Pb. Other types are introduced to identify (among others) centred text, right-justified text, or titles. |
| L | Labels. The second character specifies whether it is a label of a herb, zodiac element, nymph, etc. etc., and it is L0 if this is not near any drawing element. |
| C | Circular text. Cc for clockwise and Ca for anti-clockwise. |
| R | Radial text. Ri for inward writing and Ro for outward writing. |
Based on the above rules, the total number of loci in the MS could be established. After adjusting the loci in each of the files according to the rules listed above, the completeness of each transliteration file could be established, in terms of the number of loci covered. The analysis showed that the "LZ" transliteration, which benefited strongly from the work of Theodore Petersen, was most complete. It lacked only:
I decided to extract my own transliteration from the LZ combined effort, and this will be called ZL in the following. The few loci that were missing in LZ were added to this file. I am continually updating it, and it is presently at stable issue 3b.
In May 2025 it was pointed out to me that one locus (a label on f89v2), present in several of the transliterations, is actually a word shining through from the other side of the folio. In transliteration files maintained by myself (namely 'ZL' and 'RF') this locus has been removed from the files. It has also been removed from all counts in the following, and it means a reduction of the total number of loci to 5388.
For transliteration files from other authors, I decided that I should not remove this locus, but rather mark it as 'invalid' in the file, using a dedicated code.
Furthermore, as a result of recently available multi-spectral scans, more characters from the alphabet tables on f1r can now be discerned. At the same time, they can now also be positively identified as later additions, most probably by Johannes Marcus Marci (8). Three of these characters were included in the total locus count, and appeared only in files maintained by myself, so they could be removed, reducing the total number of loci to 5385 (9).
The counts in the following table reflect the status of the files after a considerable verification exercise in 2019-2020, and the above-mentioned changes in 2025.
| Code | Description | Locus count | Percentage |
|---|---|---|---|
| FSG | The FSG transliteration. | 4060 | 75.4 |
| C-D | The original transliteration of D'Imperio and Currier | 2196 | 40.8 |
| Vnow | The updated version of this file, made during the earliest years of the Voynich MS mailing list. | 2550 | 47.4 |
| IT | The transliteration by Takeshi Takahashi included in the interlinear file. | 5215 | 96.8 |
| LSI | The Landini-Stolfi Interlinear file | 5341 | 99.2 |
| LZ | The unpublished Landini-Zandbergen transliteration | 5382 | 99.9 |
| GC | The v101 transliteration file. | 5367 | 99.7 |
| ZL | The "Zandbergen" part of the LZ transliteration effort. | 5385 | 100 |
The new format is based on minimal adjustments to the conventions used by Gabriel Landini and myself in the frame of our transliteration efforts in 1998-1999, which also went into the format definition of the interlinear file, where they can still be found (which is why these details are still presented here). There were a number of issues to be resolved, mainly related to the character set of the v101 alphabet, which was shown here. Problems existed with the following characters:
| Char | Clash | Solution |
|---|---|---|
| ( | This is a character in v101, so it cannot be used as a ligature marker | Use { } for ligature markers, and <! > for in-line comments. |
| & | This is a character in v101, so it cannot be used to represent high-ascii codes. | Use @ for high-ascii codes. |
| * | This is a character in v101, so it cannot be used to mark an illegible character. | Use ? for illegible characters. |
| \ | This is a character in v101, so it cannot be used to indicate line wrapping (continuation of a locus on the next line). | Use / for this purpose. |
| | | This is a character in v101, so it cannot be used to separate alternative options between [ ] brackets | Use : for this purpose. |
The result of this exercise was the definition of a new format, which I have called IVTFF (Intermediate Voynich Transliteration File Format). The complete format description (version 2.0.2 of July 2025) may be found in this PDF document The version nr refers to the document. The file format is not significantly different from version 2.0. (Note that the earlier version 1.7 may still be found on the legacy page).
The table below summarises the most important conventions used for this format.
| # (hash) at start of line | The entire line is a comment. |
|---|---|
| <f ... > | With the < character in the first position of the line. This is a locus indicator, and appears at the start of each text segment. It explains where this text is to be found. The format of locus indicators is explained further below. |
| <! ... > | With the < *NOT* in the first position of a line. All text between the delimeters is a comment. This may appear anywhere in a line. |
| . | A word space (word separator). |
| , | An uncertain word space. |
| [ ... ] | Used for alternative or uncertain reading. [a:o] means it could be an a or an o, but it is not certain. The options must be separated by a colon (:), and there can be more than two options, e.g. [r:s:d]. If possible, the most likely option should be the first one. |
| { ... } | A ligature of standard characters. Only used with the Eva and Frogguy alphabets |
| @nnn; | A high-ascii code. nnn must be in the range 128 to 255 |
| <-> | A drawing intrusion in the text. This also implies a word space. If <~> is used instead of <-> it means that the text left and right of the intrusion is not aligned vertically. |
| <%> at start of line. | Start of a paragraph. |
| <$> at end of line. | End of a paragraph. |
| / at end of line | This locus is continued on the following line in the file, which must have a / in the first position. |
| ? | A single illegible character. |
| ??? | An uncertain number of illegible characters. |
For additional conventions and details, see the format definition.
There are three types of locus indicators:
| <f17r> | A locus indicator without a period means the start of a new page, in this case f17r. There will be no Voynich MS text following this, but there may be a comment, with metadata referring to the entire page. |
|---|---|
| <f17r.N,@Ab> | This is the start of a piece of text of locus type 'Ab'. The value of N must increase monotonously, starting at 1, for each page. @ is a placeholder for various different symbols, which is explained in the detailed format description. The locus type Ab is listed in Table 10 below. |
| <f17r.N,@Ab;T> | Same as above, but identifiying the source of the transliteration (a person or a group) by the character T. |
All loci have been classified into different types, which are identified by two characters. Following is the distribution of the loci over these types, for the entire MS (10).
| Type | Subtype | Meaning | Count |
|---|---|---|---|
| P | - | All running text in paragraphs | 4130 |
| - | P0 | Standard left-aligned text | 3885 |
| - | P1 | Lines indented significantly due to drawings or other text | 72 |
| - | Pb | Dislocated text in free-floating paragraphs | 134 |
| - | Pc | Centred lines in normal paragraphs | 17 |
| - | Pr | Right-justified lines in normal paragraphs | 12 |
| - | Pt | "Titles" in normal paragraph text (see here) | 10 |
| L | - | All labels and dislocated words or characters | 1029 |
| - | L0 | Individual words or characters not near a drawing element | 297 |
| - | La | Labels of astronomical or cosmological elements which are not stars or zodiac labels | 7 |
| - | Lc | Labels of containers in the pharmaceutical section | 40 |
| - | Lf | Labels of herb fragments in the pharmaceutical section | 194 |
| - | Ln | Labels of nymphs in the biological/balneological section | 63 |
| - | Lp | Labels of full plants in the herbal section | 3 |
| - | Ls | Labels of stars | 76 |
| - | Lt | Labels of 'tubes and tubs' in the biological/balneological section | 47 |
| - | Lx | Individual pieces of marginal (external?) writing | 3 |
| - | Lz | Labels of zodiac elements | 299 |
| C | - | All writing along circles | 84 |
| - | Ca | Anti-clockwise writing along circles | 1 |
| - | Cc | Clockwise writing along circles | 83 |
| R | - | All writing along the radii of circles | 142 |
| - | Ri | Inwards writing along the radii of circles | 75 |
| - | Ro | Outwards writing along the radii of circles | 67 |
| Total | 5385 | ||
The following table summarises the coverage of these loci in each of the five main transliteration files.
| Code | P | L | C | R | Total |
|---|---|---|---|---|---|
| FSG | 3962 | 98 | 0 | 0 | 4060 |
| C-D | 2175 | 21 | 0 | 0 | 2196 |
| IT | 4119 | 883 | 72 | 142 | 5216 |
| GC | 4130 | 1011 | 84 | 142 | 5367 |
| ZL | 4130 | 1029 | 84 | 142 | 5385 |
An additional feature of the IVTFF format is the use of so-called page variables. Further above, the page start locus type was introduced. On these lines, no transliterated text is allowed, but there can be a dedicated comment setting page variables, which may look like this:
<f1r> <! $Q=1 $P=1 $I=T $L=A $C=1 $H=1 >
This dedicated comment sets a number of variables ($Q, $P etc.) to certain values for the whole page. This allows software to select or de-select pages based on these settings. An example of this is the transliteration file (pre-)processing tool "ivtt" which is introduced further below, and which has this capability built in. The meaning of the most important page variables is included in the table below. A complete list with all possible values is given in the IVTFF format definition.
| Variable | Meaning | Values |
|---|---|---|
| $Q | Quire | A (=1), B (=2), C (=3), .... T (=20) |
| $P | 'Page in quire' | A-X, in increasing order, depending on the quire |
| $I | Illustration type | T =text-only, H =herbal, Z =zodiac, B =biological, etc. etc. |
| $L | Currier language | A or B |
| $H | Hand | 1 - 5, according to Fagin Davis |
![]()
The IVTFF format had been at a stable version 1.7 since April 2020. This format left some freedom in certain details, and as a consequence it had not been followed strictly in most of the files. For a fully consistent automated processing, it was necessary to resolve these minor issues, which was achieved by the (also minor) update to version 2.0.
The main issue was related to the use of the code <-> to indicate that the text is interrupted by a drawing element, most commonly part of a plant drawing. This code replaces the minus sign that was already used for this purpose in transliteration files in the 1990's. When this occurs, there is usually a period (indicating a word space) directly before or after the <-> , but not always. To resolve this, the new rule is that the <-> code implies a word space.
Secondly, the code <~> had been introduced to indicate a bad vertical alignment between consecutive words. This has only ever been used in the ZL file, and at the location of a drawing intrusion of the text. This has usually been represented as <-><~> . The new rule is that the <~> code implies a <-> , and thereby a word space.
Furthermore, especially older files could have periods (word spaces) at the beginning or end of a line, and newer files had <-> codes at the beginning or end of a line, all of which are not meaningful. The format consolidation therefore introduces the following rules:
A further change (affecting only the ZL file) is that it is now obligatory for all uncertain readings to include a colon, i.e. [ao] is no longer allowed, and this shall be written as [a:o].
There are other very minor rule changes, which are all included in the format definition, for which see IVTFF format 2.0.1 definition.
All transliteration files using IVTFF format 2.0 (or higher) are accessible through tables here and here.
(See also the descriptions in the ReadMe file.)
In the course of the transliteration collaboration with Gabriel Landini, I developed a tool to pre-process transliteration files. At the time, I made very extensive use of this tool, among others to do the analyses presented here, here and here, but since our transliteration was never published, this tool was never used by anyone else.
This tool has been converted in order to process files in the IVTFF format. The new version of this tool has been named (prosaically) IVTT (Intermediate Voynich Transliteration Tool). Its latest user manual (v.2.4) is provided here, and the latest source code in C is provided here. Users also need to be familiar with the IVTFF format definition.
The tool has been kept up to date with respect to all format changes, some of which were briefly described above. Versions 2.0 and higher process IVTFF files in the format version 2.0 and 2.0.1. The latest version of the software is 2.4, dated 7 September 2025. Versions below 2.4 should should not be used, as some bugs were disovered related to options I had rarely used.
An interactive, on-line browser-based version of ivtt was created in February 2026, by Jeremie Bornais. This is based on ivtt version 2.4, and is available via >>this link.
The earlier software version 1.3, which processed IVTFF files using format version 1.7, can still be retrieved through the legacy page.
Rather than explaining the usefulness of this tool by duplicating information from its user guide and the IVTFF format definition, I prefer to show this by giving a few simple examples.
One of many uses of the tool is to select specific parts of a transliteration file. For example, the command:
ivtt +QO +@Lc ZL.txt
Can be used to extract all container labels in quire 15 from the ZL transliteration file. The result might look like this (depending on the version of the ZL file):
<f88r> <! $I=P $Q=O $P=C $L=A $H=4> <f88r.1,@Lc> otorchety <f88r.12,@Lc> otaldy <f88r.23,@Lc> ofyskydal <f88v> <! $I=P $Q=O $P=D $L=A $H=4> <f88v.1,@Lc> okalyd <f88v.11,@Lc> otoram <f88v.27,@Lc> daramdal <f89r1> <! $I=P $Q=O $P=F $L=A> <f89r1.1,@Lc> okchshy <f89r1.11,@Lc> ykyd <f89r1.24,@Lc> ykocfhy <f89r2> <! $I=P $Q=O $P=G $L=A> <f89r2.1,@Lc> odory <f89r2.9,@Lc> otold[:y] <f89r2.16,@Lc> korainy <f89r2.29,@Lc> okain <f89r2.30,+Lc> yorain<!below previous> <f89v2> <! $I=P $Q=O $P=I $L=A> <f89v2.1,@Lc> choeesy <f89v2.11,@Lc> otory <f89v2.23,@Lc> <!58a>opaloiiry <f89v1> <! $I=P $Q=O $P=J $L=A> <f89v1.1,@Lc> okoraldy <f89v1.21,@Lc> <!container>koeeorain
To remove the 'dressing' and leave only the transliterated text, the command issued above can be changed (for example) as follows:
ivtt -f1 -c3 +QO +@Lc ZL.txt
The same can be done reading the GC file:
ivtt -f1 -c3 +QO +@Lc GC.txt
or for Takeshi's transliteration:
ivtt -f1 -c3 +QO +@Lc IT.txt
The results of the three commands are shown below, next to each other:
| From ZL file | From GC file | From LSI file |
|---|---|---|
otorchety otaldy ofyskydal okalyd otoram daramdal okchshy ykyd ykocfhy odory otold[:y] korainy okain yorain choeesy otory opaloiiry okoraldy koeeorain |
okoy1ck9 okae89 of9sh98ae ohAe98 okoyap 8ayap7ae oh159 9h98 9hoF9 o8oy9 okoe89 hoyan,9 ohan 9oyan 1oCs9 okay9 ogaeoZ9 ohayae79 hoCoy,an |
otorchety otaldy ofyskydal okolyd otoram daramdal okchshy ykyd ykocfhy odory otoldy korain.y okain yorain choeesy okory opaloiiry okoraldy koeeorain |
As another example, one may quickly see that centred lines in normal paragraph text occur equally in pages written in Currier language A and in Currier language B:
ivtt -x7 +@Pc +LA ZL.txt >> ytchas oraiin chkor dainod ychealod ychekch y kchaiin saiinchy daldalol sam chorly otchodeey dorain ihar okar sheey shekealy teol cheol otchey ???cheor cheol ctheol cholaiin chol qkar
and
ivtt -x7 +@Pc +LB ZL.txt >> oteor aiicthy oteol cholkal qokal dar ykdy pchedy chetar ofair arody yteched ar olkey okeoam s ar chedar olpchdy otol otchedy dar oleey ol yy otar chdy dytchdy otoiir chedaiin otair otaly
![]()
Bitrans is a tool that can perform text substitutions in any plain text file. In addition, it provides specific support for files in the IVTFF format. It is a convenient tool to change the transliteration alphabet of any transliteration file (whether IVTFF-formatted or not) from one to another. The user achieves this by providing a table of equivalences, a so-called 'rules file'. The tool can apply this table in both directions.
Rules files for the common transliteration alphabets are provided with the tool. For this,
simply visit the
dedicated directory.
Example: STA-v101_def.bit converts files using the STA alphabet (for which
see here)
to the v101 alphabet. In addition, a
Zip file
collects all rules files present in this directory, and allows a user to download them all
at once.
This tool also allows the user to define his own transliteration alphabet, and easily convert any of the existing transliterations into it. A very simple example of that was given here.
The user latest guide (version 1.5) of bitrans is provided here, and the latest source code in C (version 1.5 of 06/12/2025) is provided here.
Please Note that earlier bitrans versions had several bugs and should not be used.
See also the ReadMe file.
![]()
Several more-or-less complete transliterations of the Voynich MS text have been made, and are presented in a table on the main page. However, some text in the MS is missing in all of them. It is either not represented at all, or represented by the sequence "???", meaning: an unknown number of illegible characters.
Here, we are not concerned with text on pages that have been lost (such as e.g. folio 12 or folio 74), but with text that is on the extant folios.
We are also not concerned with text that we can see clearly, but we can't figure out which characters are there. An example of that is part of the text around the sun face at the bottom of folio f68r2, see lower left quadrant in the following figure. Here, we can't even decide which part of the text is in the unknown script, and which part is 'cleartext'.

What we are concerned with here is text that we know is there or should be there, but it hasn't been transliterated (yet) because we can't see it properly. The text may not have been photographed, for example, or it may be behind layers of paint, or it may have been damaged.
To assess this, it is useful to first present the list of sources from which the transliterations may be made:
| Code | Source | Comment |
|---|---|---|
| A | The original MS | The original MS has limited accessibility, but could be consulted in principle to provide the "final answer". Some illegible parts will also be irrecoverable from the original. |
| B | The Siloé facsimile | This has been produced on the basis of new photographs which may be more complete than the Beinecke 2014 digital scans, but some parts remain equally invisible in the final product. |
| C | The 2014 scans at the Beinecke digital library | This is the 'default' source but parts of the text are invisible for several reasons. |
| D | The 2004 digitial scans | The earlier scan is still available. In some parts it is worse, and in other parts better than the 2014 scans. Some zodiac pages are not visible at all. |
| E | The B/W copyflo from the 1970's | This is of generally lower quality, but the zodiac pages were flattened in this copy. |
| F | The Friedman copy | Probably the oldest available copy made from original photostats, but the quality of these 'copies of copies' is even lower than the copyflo. |
| G | The Petersen hand transcript | This is not a true source, but includes his interpretation of the writing. Its usefulness is that he has consulted the original MS in the 1930's, in order to complete parts that were not clear in his photostats. |
The 'best' source to start from is "C", the set of digital scans at the Beinecke digital library, because it is easily acessible and nearly complete. The list of badly readable parts may be made starting from this source, and is presented below. In the table, "Locus" refers to the identification of the item in the IVTFF transliteration. "Problem description" is usually based on what we see in the Beinecke 2014 scans (source "C").
This is work that is still very much in progress....
| Folio | Locus | Item | Problem description |
|---|---|---|---|
| f67v2 | 21 | Cosmological page. Vertical label near the four coloured faces in the lower left corner of the page | It is under the paint and not visible in "C" or "D". It is barely visible in "B". "G" has part of it. |
| f71v | 1 | First "Taurus" zodiac page. Some words in the outer circle near 03:00 | The words are hidden in the fold |
| f72r3 | 1 | "Cancer" zodiac page. 1-2 words in the outer circle near 01:00 | The words seem obliterated in the fold |
| f72r3 | 14 | "Cancer" zodiac page. Part of a word in the second circle near 02:00 | The part is hidden in the fold |
| f72r3 | 20 | "Cancer" zodiac page. Part of a label near 03:30 | The part is hidden in the fold |
| f72v3 | 1 | "Leo" zodiac page. Several different parts of the outer circle | Several parts are hidden by folds. The boundary with the next page (showing Virgo) is actually not hidden, but there is an interruption in the text as the circles did not fully fit on the pages. |
| f72v3 | 20 | "Leo" zodiac page. Several words around 10:00 in the second circle | They are hidden by the fold. |
| f72v2 | 1 | "Virgo" zodiac page. Numerous words around 03:00 in the outer circle | They are beyond the folded edge of the page. The boundary with the previous page (showing Leo) is actually not hidden, but there is an interruption in the text as the circles did not fully fit on the pages |
| fRos | 1 | Rosettes page. Label in upper left corner. | It is barely visble. It has been recorded in source "H". |
| fRos | 47 | Rosettes page. Left centre circle. | There are two bad parts due to the horizontal fold. Can be largely recovered from "B" and "D". |
| fRos | 133 | Rosettes page. Bottom right circle around 09:00. | There are major parts of the text missing due to the badly damaged fold. |
| f86v4 | 1, 2 | Cosmological page. Two outer circles near 10:00. | Both very minor issues, due to crease in page. |
| f101v | 19 and ff. | Pharmaceutical page. Central parts of all horizontal lines of text. | Most significant issue in the entire MS. Large parts of the horizontal text have become obliterated due to wear of the fold. |
| f102r2 | 15. | Pharmaceutical page. Bottom word in the bottom jar. | Word is under the paint and almost impossible to read. (Other words are somewhat less affected). |
| f103r | 5-9 | Text page with marginal stars. Numerous words near the upper right corner. | Words are covered by a significant stain. |
| f116r | 43,44 | Text page with marginal stars. Some characters near start of lines. | Characters have been eaten away by insects. |
![]()
|
|
|
|
|